
Мат и оскорбления
13 постов
13 постов

6 постов
8 постов
11 постов
7 постов

8 постов
12 постов
11 постов
4 поста
4 поста
5 постов
6 постов
5 постов
Попросили меня недавно прокомментировать вот такой пост:
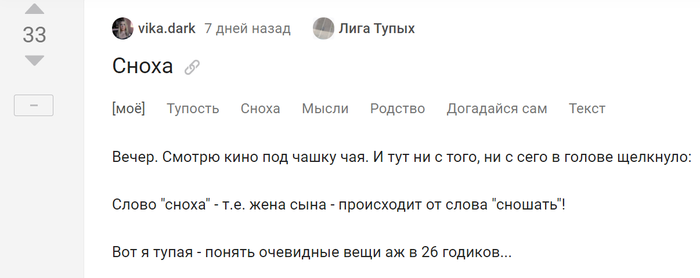
Сразу скажу, что интуиция подвела @vika.dark. Во-первых, всегда надо помнить, что внешне похожие друг на друга слова не обязательно родственны, сходство может быть и случайным (см. отдельный пост об этом). Во-вторых, нельзя рассматривать языковые факты изолированно, системный подход – это наше всё.
Что это значит на практике? Для начала то, что если учёный хочет установить этимологию русского слова, он обязательно проверит, как оно выглядит в древнерусском и в диалектах, а также то, есть ли у этого слова родственники в других славянских языках.
Сразу выясняется, что в древнейших русских памятниках мы находим форму снъха. Например, в надписи №307 (1170-1180 гг.) из киевского Софийского собора:
многопечалнаѧ андрѣева снъха
Напомню, что буква ъ в раннем древнерусском в отличие от современного русского обозначала особый гласный звук, который в одних позициях исчез, а в других перешёл в о. Например, сънъ > сон, мъхъ > мох.
Теперь заглянем в другие славянские языки. Родственники нашей снохи там вполне представлены: словенское snaha, сербохорватское снаха, польское диалектное sneszka /снэшка/ с закономерным отражением *ъ (ср. слвн. mah, схр. мах, пол. mech /мэх/ «мох»). Это даёт нам основания восстанавливать праславянскую форму *snъxa.
На первый взгляд, проблематичны болгарская и чешская формы: снаха и snacha /снáха/ соответственно. Ведь в этих языках мы бы ожидали снъха и snecha /снэха/. Объясняется это тем, что в обоих языках это заимствования из сербохорватского. В болгарских диалектах мы находим закономерное снъха, а в чешский snacha попало лишь в XIX веке, когда будители чешского народа активно тянули лексику из других славянских языков (о заимствованиях из русского я делал отдельный пост).
Уже на этом этапе мы можем попрощаться с мыслью о родстве снохи и сношать. Первое – потомок праславянского *snъxa. Второе явно родственно носить (праславянское *nositi), на что напрямую указывает глагол сноситься «входить в сношения, переговоры, устанавливать связь», и законы историческое фонетики не позволяют считать сноху и сношать родственными.
Также я должен напомнить, что «сексуальное» значение у сношаться и сношения – вещь поздняя, совсем недавняя. Первоначально сношение – это «связь, общение», чаще всего дипломатическое. Первые примеры известны с XVIII века:
И, едучи Полшею, чтоб король ни с кем сношения с поляками не имел, також бы полякам обид никаких не чинил и все потребное покупали б от поляков за свои деньги. [А. М. Макаров (ред.). Гистория Свейской войны (Поденная записка Петра Великого) (1698-1721)]
Хотя так знатной город Оренбург строить начат, токмо без всякого архитектурнаго порядка, того ради сим императорской Академии наук почтенно представляю, чтоб химика по сношению с Медицинскою коллегиею, живописца и архитектора искусных благоволила приискать, а между тем хороших на немецком языке архитектурных книг, купя, прислать. [В. Н. Татищев. Письмо в Академию наук (1737)]
И всего каких-то сто лет назад М.М. Бахтин употреблял слово сношаться безо всякого сексуального подтекста:
Ибо наружность должна обымать и содержать в себе и завершать целое души ― единой эмоционально-волевой познавательно-этической установки моей в мире, ― эту функцию несет наружность для меня только в другом: почувствовать себя самого в своей наружности, объятым и выраженным ею, я не могу, мои эмоционально-волевые реакции прикреплены к предметам и не сношаются во внешне законченный образ меня самого. [М. М. Бахтин. Автор и герой в эстетической деятельности (1920-1924)]
Но вернёмся к снохе. Какова этимология праславянской формы *snъxa? Идём тем же путём: проверим, есть ли родственные слова в других индоевропейских языках. И они есть: санскритское snuṣā́ /снушáа/, латинское nurus, древнегреческое νυός /нюóс/, армянское устаревшее նու /ну/, немецкое устаревшее Schnur /шнур/ и другие. На первый взгляд они на нашу сноху не очень похожи, но здесь опять же надо знать законы исторической фонетики.
Так, нам известно, что праславянский звук *ъ продолжает более старый *u, а *x – из *s в определённых условиях. Это значит, что в раннем праславянском наш корень звучал как *snus-.
Теперь возьмём латинское nurus. Известно, что в латыни -s- между гласными перешёл в -r-. Об этом сообщал, например, Варрон:
Во многих словах, в которых древние произносили s, позже стали произносить r: foedesum – foederum «союзов», plusima – plurima «величайшая», meliosem – meliorem «лучшего», asenam – arenam «песок».
Это значит, что nurus вполне может быть из *nusus. Идём дальше. Звук s- исчезал в латыни и греческом в начале слова перед рядом согласных, включая n. Пара примеров:

Получается, что мы можем продолжить ряд: nurus < *nusus < *snusos. К тому же *snusós можно легко возвести и греческое νυός /нюóс/, поскольку s в греческом выпадал между гласными, а всякий u переходил в ü.
Как я уже писал выше, наша *snъxa тоже из *snus-. Отличия в окончании между праславянским с одной стороны и латынью и греческим с другой объясняются легко. В латыни и греческом существительные на -us / -ος были по большей части мужского рода, но могли быть и женского (это как раз случай nurus / νυός), праславянский же несколько упростил картину: все подобные существительные были переведены в более обычное для женского рода склонение на -a.
Выходит, что долгие тысячи лет (6-7 минимум) наши предки называли жену сына одним и тем же словом, которое не так уж сильно изменило свой облик за это время: *snusós > *snъxa > сноха. И лишь распад традиционной модели семьи привёл к тому, что это слово постепенно стало уходить из нашего обихода. По сравнению с этой древностью слово сношаться появилось будто вчера.
Реконструкция праиндоевропейских терминов родства (Mallory J.P., Adams D.Q. The Oxford Introduction to Proto-Indo-European and the Indo-European World. Oxford, 2006. P. 217):
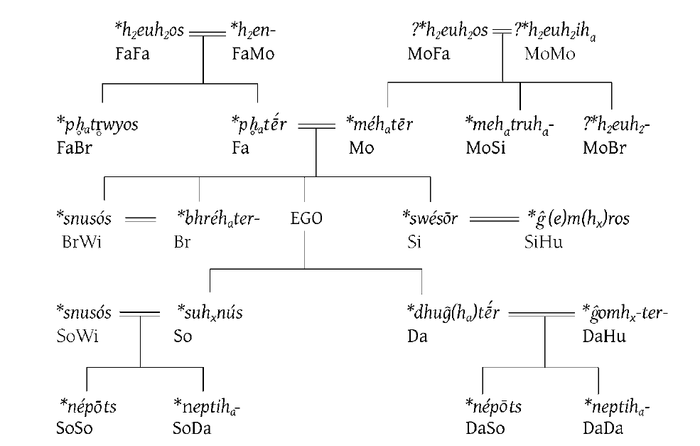
Но можно ли пойти дальше, и найти дальнейшую этимологию праиндоевропейского *snusós? С этим уже сложнее: родственников этого слова на более глубоком уровне мы не знаем. Было сделано несколько попыток связать его с другими праиндоевропейскими корнями, но они скорее гадательны. Наиболее любопытных отсылаю к следующим источникам:
Трубачёв О.Н. История славянских терминов родства и некоторых древнейших терминов общественного строя. М., 2009. С. 131-133.
Wodtko D.S., Irslinger B., Schneider C. Nomina im Indogermanischen Lexikon. Heidelberg, 2008. S. 625-626.
Краткое резюме:
1. Сноха и сношать никак не родственны. Сходство случайно.
2. На самом деле русское слово сноха является потомком праславянского *snъxa (ъ – особый гласный), а то – праиндоевропейского *snusós.
3. Сношаться и сноситься образованы от носить. Первоначально эти глаголы не имели «сексуального» значения, его они приобрели сравнительно недавно.
Но что же делать человеку, который просто размышлял об этимологии того или иного слова, и его внезапно осенило? Во-первых, помнить об эффекте Даннинга-Крюгера. Во-вторых, осознавать, что уже двести лет специально обученные люди в поте лица двигают вперёд индоевропейскую и славянскую этимологию. Поэтому пришедшую вам в голову идею следует сверить, скажем, со словарём Фасмера. Сошлось? Отлично! Не сошлось? Ничего страшного, этимология – это не столь лёгкое занятие, как кажется на первый взгляд.
Без сомнения написание сдесь – одна из самых ненавистных для граммар-наци ошибок:
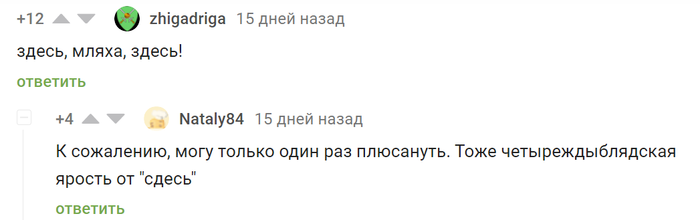
Но что, если я скажу вам, что с исторической точки зрения правильнее было бы писать сдесь?
Впрочем, давайте по порядку. В древнерусских памятниках на месте здесь мы находим зде. Более того, именно такая форма, zde, сохранилась в чешском языке.
И приехавши не вси плъци к граду, начаша кличюще въпрашивати, въпиюще и глаголюще: "Есть ли зде князь Дмитрий? "Они же из града с заборолъ отвѣщавше, рекошя: "Нѣтъ". [Повесть о нашествии Тохтамыша (1382-1400)]
"Zde to není špatný," navazoval dál Švejk rozmluvu, "tahle pryčna je z hlazeného dříví".
― Здесь недурно, ― попытался завязать разговор Швейк. ― Нары из струганого дерева.
Из этого следует, что здесь – это сложение зде + сь, где сь – это старое местоимение со значением «этот». Читателю оно лучше известно в форме с наращением: сей. Аналогичное -сь мы находим в просторечном вчерась и устаревшем днесь «сегодня».
При этом само зде появилось на месте более древнего сьде, известного из древнейших древнерусских и старославянских памятников:
тꙑ стани тамо или сѧди сьде
«ты стань там, или садись здесь» (Христинопольский апостол, XII век)
Отмечу, что в старославянском и раннем древнерусском буквы ъ и ь обозначали особые гласные звуки, которые условно принято называть редуцированными. В определённое время редуцированные гласные стали исчезать, что оказало серьёзное влияние на звуковой облик многих слов. До падения редуцированных сьде произносилось в два слога: сь-де. После того, как звук ь исчез, с и д оказались в непосредственном соседстве. При этом с – глухой звук, а д – звонкий. Русский язык такие сочетания не любит, в группе согласных все должны быть глухими или звонкими (единственный звук, на который это правило не распространяется – в). Соответственно, с пришлось озвончиться. А звонкая пара к с – это з. Так из сьде мы получили зде.
Несколько аналогичных примеров для понимания:
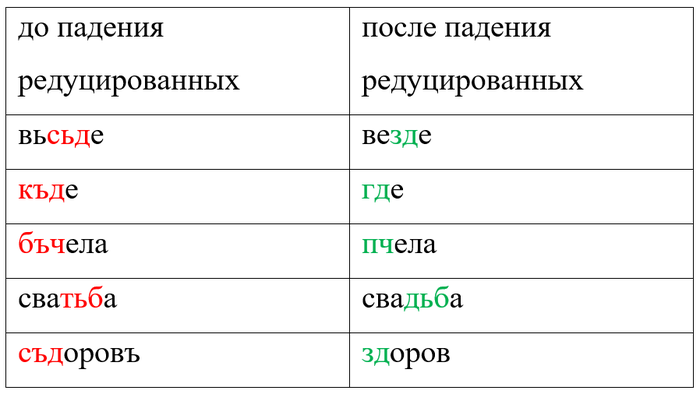
Что касается сьде, то оно не случайно рифмуется с къде «где» и вьсьде «везде». Более того, из древнерусских памятников мы знаем слова инъде «в другом месте» (ср. чешское jinde /йиндэ/ «в другом месте»), овъде «там» (ср. сербохорватское ovdje /óвдйе/ «здесь»), онъде «там».
Во всех этих словах можно выделить частицу -де, родственники которой нам известны из других индоевропейских языков. Например, из древнегреческого:
οἶκος /ойкос/ «дом» – οἶκόν-δε /ойкон-дэ/ «домой»;
οὐρανός /уранос/ «небо» – οὐρανόν-δε /уранон-дэ/ «на небо»;
φυγή /п˟югээ/ «бегство» – φύγα-δε /п˟юга-дэ/ «в бегство».
Несложно отождествить и первую часть: сь – это всё то же местоимение со значением «этот». Аналогичным образом къ из къде – это вопросительное местоимение, которое с другой частицей стало звучать как къто > кто. С прочими словами всё ещё очевиднее:
вьсьде = вьсь «весь» + -де;
инъде = инъ «другой» + -де;
овъде = овъ «тот» + -де,
онъде = онъ «тот» + -де.
Выходит, что здесь = сь + де + сь, где сь значит «этот», а -де – частица со значением места. Дублирование сь нас смущать не должно, у местоимений и наречий такое случается. Например, в русском: вот этот вот. Или в чешском: tenhleten /тэнғлетэн/ «этот» (дословно что-то вроде «этот вот этот»).
После падения редуцированных слово сьде стало звучать, а затем и писаться, как зде, что закреплено в современной орфографии. Те же самые фонетические процессы произошли, например, в глаголе съдѣлати, который мы сейчас произносим как /зделать/, однако пишем как сделать, поскольку было решено приставку с- всегда писать одинаково, вне зависимости от звучания.
Выходит, что писать здесь, но сделать – несколько непоследовательно. Логичнее было бы здесь и зделать (в соответствии с произношением) или сдесь и сделать (в соответствии с происхождением). Тем более, что во время орфографической реформы 1918 года было решено приставки без-/бес-, воз-/вос-, из-/ис-, раз-/рас-, через-/черес- писать в соответствии с произношением: возделать, но вострубить, разделать, но раструбить. До революции писалось по иным правилам: разсказъ, возсіять, изсякнуть, безполезный, черезчуръ.
Если бы реформаторы распространили это правило и на приставку с-, то сейчас граммар-наци ругались бы на тех, кто пишет сделать, а не зделать.
Ещё нелогичнее в рамках текущих правил писать свадьба при наличии однокоренных сват и сватать. Ведь мы пишем волшба, косьба и просьба (волшебник, косить, просить), а не волжба, козьба и прозьба. Но это уже другая история.
Источники:
Słownik prasłowiański. 1979. Tom 3, strona 26.
Dunkel G.E. Lexikon der indogermanischen Partikeln und Pronominalstämme, 2014. Band 2, Seite 148.
Продолжаю цикл постов по «экономической» этимологии. Прошлый пост был о слове платить, теперь же поговорим о купить и купце.

Как и платить, оба этих слова праславянской древности, то есть как минимум полторы тысячи лет тому назад наши предки уже хорошо знали, что такое торговля.
Для наглядности покажу, как выглядят потомки четырёх праславянских слов, связанных с торговлей, в нескольких славянских языках.
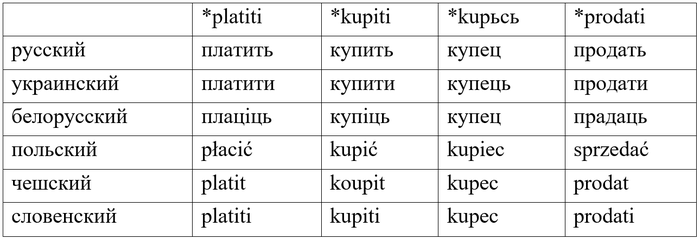
Однако, если глаголы платить и продать – слова исконно славянские, то в купить этимологи видят заимствование.
Дело в том, что в германских языках есть аналогичный корень с той же семантикой: готское kaupon «торговать», древнескандинавское kaupa «покупать», немецкое kaufen «покупать», Kaufmann «купец», древнеанглийское ċēapian «торговать, покупать», современное английское cheap «дешёвый» и многие другие.
Эти данные позволяют реконструировать для прагерманского языка слова *kaupaz «покупка», *kaupamannz «купец», *kaupjaną / *kaupōną «покупать» и некоторые другие от того же корня.
Соотношение гласных корня между праславянским *kupiti и прагерманским *kaupjaną нас смущать не должно: в праславянском *au и *ou давали *u. Зато прагерманские согласные здесь не могут напрямую соответствовать славянским (об этом см. отдельный пост).
Это значит, что мы имеем дело с заимствованием. Поскольку корень реконструируется для прагерманского, то заимствовать должны были славяне у германцев (почему так, я рассказывал в посте об этимологии слова князь). Вероятнее всего, в праславянский это слово попало из готского.
Однако и у германцев корень *kaup- заимствован. Как это чаще всего бывает, из латыни, в которой было слово caupō /кáўпоо/ «кабатчик, трактирщик; торговец (презрительно)». К слову сказать, нейтральное обозначение купца в латыни – mercātor /мэркáатор/, причём корень этого слова германоязычные народы тоже заимствовали (а от них позднее и мы – ярмарка, маркетолог, маркетинг).
В древнегреческом есть слово, похожее на латинское: κάπηλος /кáпээлос/ «мелкий торговец, лавочник, торговец в разнос; трактирщик, кабатчик; торгаш, плут, мошенник». Поскольку греческое и латинское слова нельзя свести к одной праформе, весьма вероятно, что в обоих языках – это заимствование из какого-то вымершего средиземноморского языка (и в греческом, и в латыни таких случаев хватает).
Что интересно, финские слова kauppa «магазин» и kaupunki «город» заимствованы у скандинавов, и корень в них всё тот же.
Теперь сведём всё в упрощённую схему. Линия означает наследование или деривацию, а стрелочка – заимствование.
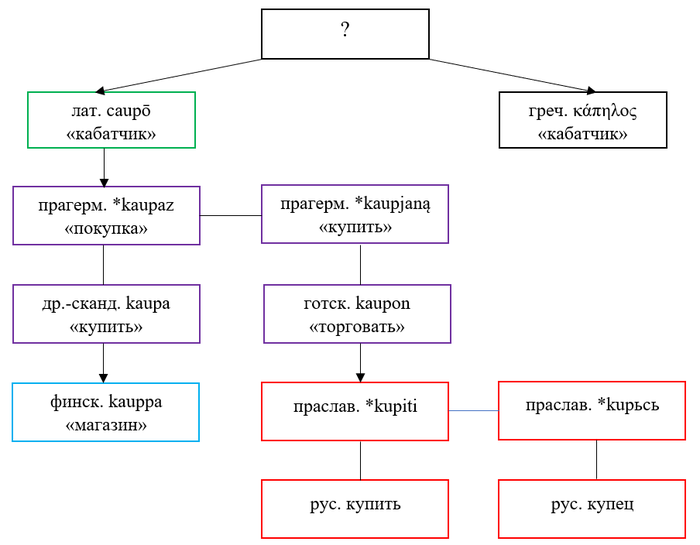
Литература:
Этимологический словарь славянских языков. Выпуск 13. М.: Наука, 1987. С. 109-112.
Beekes R. Etymological Dictionary of Greek. Leiden – Boston: Brill, 2010. P. 638.
Orel V. A. Handbook of Germanic Etymology. Leiden – Boston: Brill, 2003. P. 211.
Pronk-Tiethoff S. The Germanic Loanwords in Proto-Slavic. Amsterdam – New-York: Rodopi. Pp. 112–113.
de Vaan M. Etymological dictionary of Latin and the other Italic languages. Leiden – Boston: Brill, 2008. P. 100.
Вышел недавно у @vetyk из @Cat.Cat пост «Какие времена русский язык потерял», и @GRimZZZ попросил меня его прокомментировать. В посте рассказывается о том, что в древнерусском было 4 прошедших времени, а в современном осталось лишь одно. Это верно, но в силу несколько однобокой подачи материала и венчающей пост картинки, у некоторых читателей, несмотря на все оговорки автора, сложилось превратное представление о реальном положении вещей.
Я решил, что тема заслуживает несколько более подробного разбора, который позволит заодно ответить на вопрос, который мне неоднократно задавали в комментариях: правда ли, что языки со временем упрощаются?
Чтобы ответить на этот вопрос, надо взять временной период побольше. Как известно, русский является потомком древнерусского. Древнерусский – праславянского, а праславянский – праиндоевропейского. С праиндоевропейского мы как раз и начнём.
В раннем праиндоевропейском глагольная система была не особо сложной:
- 3 лица;
- 2 числа;
- 2 вида: статив (состояние) и эвентив (действие);
- 2 залога: активный и средний (когда действие направлено на субъект или в пользу субъекта речи);
- 2 наклонения (изъявительное и повелительное).
Заметьте, что категории времени не было. Поскольку в рамках статива залоги и наклонения не различались, а в повелительном наклонении не было форм первого лица, в общей сложности это даёт нам всего 22 глагольные формы, если не учитывать причастия.
Однако в дальнейшем праиндоевропейская глагольная система начинает усложняться. Во-первых, эвентив разделяется на две части уже с временны́м противопоставлением: настоящее время и аорист (прошедшее). Статив преобразуется в перфект (когда действие произошло в прошлом, но результат имеется в настоящем). Так мы получаем троичную оппозицию: настоящее время – аорист – перфект.
Появляются два новых наклонения: сослагательное (конъюнктив) и желательное (оптатив). Наконец, возникает двойственное число, что резко увеличивает количество форм. В общей сложности их теперь выходит 67.
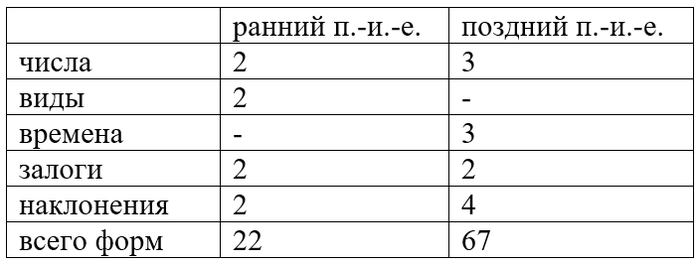
В дальнейшем, после распада праиндоевропейского языка глагольная система в языках-потомках местами упрощалась, местами усложнялась.
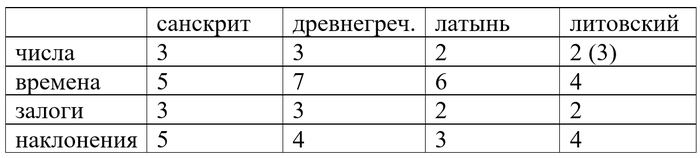
В части языков появилось будущее время, которого не было в праиндоевропейском. В прабалтославянскую эпоху оно образовывалось при помощи суффикса -s-, и это до сих пор хорошо сохранилось, например, в литовском.
Затем праславянский это будущее утрачивает. Также теряются перфект, средний залог и сослагательное наклонение. Желательное наклонение начинает использоваться в значении повелительного, а старые формы повелительного исчезают.
Однако появляются и новые формы. Возникает новое сослагательное наклонение и новые времена: имперфект (длительное или многократное действие или состояние), перфект и плюсквамперфект (действие в прошлом, предшествующее другому действию в прошлом). Появляется страдательный (пассивный залог). Кроме того, праславянский глагол обогатился инфинитивом и супином (форма, обозначающая цель при глаголах движения). В праславянском было положено начало формированию категории вида.
Выходит, что в позднем праславянском у нас была такая система:
- 3 лица;
- 3 числа;
- 5 времён (настоящее, аорист, имперфект, перфект, плюсквамперфект);
- 2 залога (действительный и страдательный);
- 3 наклонения (изъявительное, повелительное, сослагательное);
- 3 рода.
Всего получается 60 форм (не считая инфинитива, супина и причастий) в активном залоге. С учётом пассивного это число надо умножать на два. При этом там, где использовались причастия, различался род субъекта речи (как в современном русском: он делал, она делала, оно делало), что дополнительно увеличивает количество форм одного глагола, но это я уже учитывать не буду.
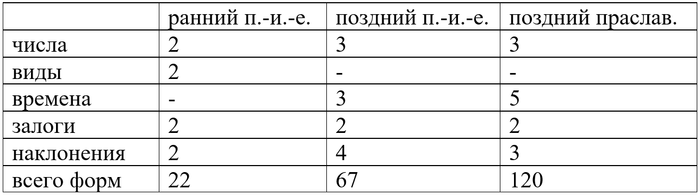
Выходит, что ранний древнерусский унаследовал от праславянского целых четыре прошедшего и ни одного будущего.

Не слишком удивляет, что уже в самую раннюю доступную для наблюдения эпоху мы видим, как исчезают прошедшие времена и формируется будущее.
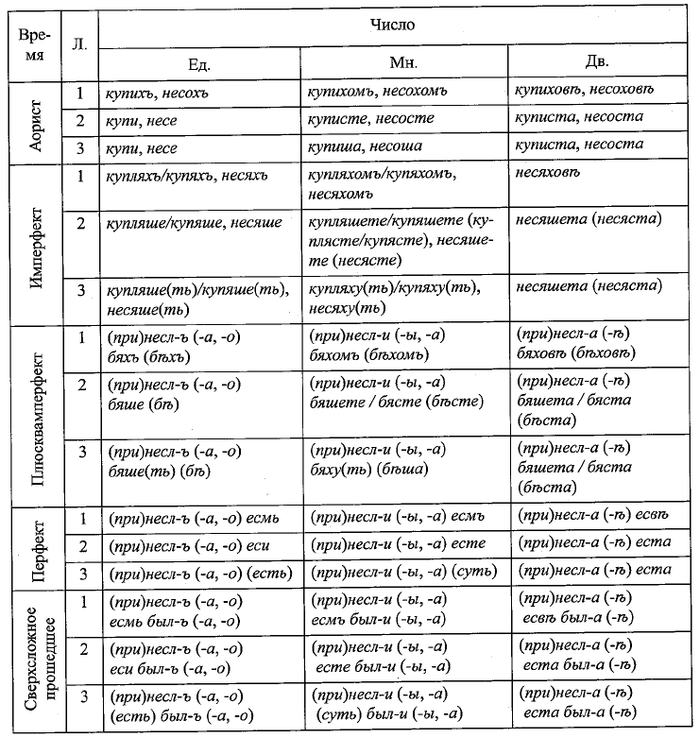
Берестяные грамоты с самого начала демонстрируют нам господство перфекта в любых значениях, а вот в других письменных памятниках обнаруживается полный набор времён. Объясняется это так, что в живой древнерусской речи XI-XII веков аорист, имперфект и плюсквамперфект постепенно исчезали, но на письме сохранялись, во многом благодаря влиянию древнеболгарских текстов (а даже в современном болгарском весь этот богатый набор прошедших времён вполне жив). Чем ближе к нам, тем чаще книжники ошибались в образовании форм аориста и имперфекта.

Для XIII века можно говорить о системе из всего двух прошедших временах – перфекте и новом, «русском» плюсквамперфекте (неслъ былъ). Последний передавал в том числе действие, не достигшее результата, или результат которого был отменён. И у нас сохранились его реликты – это конструкции типа хотел было или пошёл было. Ещё один остаток такого давнопрошедшего времени – это традиционный зачин сказок (жили-были). Как самостоятельная форма плюсквамперфект перестаёт существовать в XVI-XVII веках, и мы остаёмся с единственным прошедшим временем, бывшим перфектом.
Одна из причин, по которым стало возможно такое сокращение количества прошедших времён, это становление категории вида. Мы и в современном русском различаем точечное или результативное действие (сделал) и длительное или незавершённое (делал), но уже при помощи не аориста/имперфекта/перфекта, а благодаря противопоставлению несовершенного вида совершенному. Так что в одном месте убавилось, а в другом прибавилось.
Перейдём к будущему. Для нас кажется странным, что в древнерусском не было отдельной формы будущего времени (исключение – глагол быти – буду), но, например, финны без него прекрасно обходятся, зато у них три прошедших: имперфект, перфект и плюсквамперфект.
В древнерусском, как и в финском, формы настоящего времени могли обозначать и действие в будущем. Например, один персонаж Повести временных лет говорит:
николиже всяду на конь, ни вижю его боле того
«Никогда не сяду на коня и не увижу его больше»

Однако в древнерусском были и специализированные конструкции со значением будущего. В первую очередь это глаголы имѣти, хотѣти, начати, почати + инфинитив. Вот, например, эпизод из древнерусской «Битвы экстрасенсов» во время языческого восстания в Новгороде:
И раздѣлишася надвое: князь бо Глѣбъ и дружина его сташа у епископа, а людье вси идоша за волъхва. И бысть мятежь великъ вельми. Глѣбъ же, возма топоръ подъ скутъ, и приде к волъхву и рече ему: «То веси ли, что утрѣ хощеть быти, что ли до вечера?» Онъ же рече: «Все вѣдаю». И рече Глѣбъ: «То вѣси ли, что ти хощеть днесь быти?» Онъ же рече: «Чюдеса велика створю». Глѣбъ же, выня топоръ, и ростя ̀и, и паде мертвъ, и людие разиидошася.
И разделились люди надвое: князь Глеб и дружина его стали около епископа, а люди все пошли к волхву. И началась смута великая между ними. Глеб же взял топор под плащ, подошел к волхву и спросил: «Знаешь ли, что завтра случится и что сегодня до вечера?» Тот ответил: «Знаю все». И сказал Глеб: «А знаешь ли, что будет с тобою сегодня?» Он же ответил: «Чудеса великие сотворю». Глеб же, вынув топор, разрубил волхва, и пал он мертв, и люди разошлись.

В этом эпизоде хощеть быти означает не «хочет быть», а «будет». Тем не менее, хотя такие конструкции традиционно называют будущим сложным временем, они несли модальный оттенок. Скажем, в современном русском делаю и буду делать противопоставлены только по времени, а вот делаю и собираюсь делать отличаются модальностью, и собираюсь делать нельзя признать формой будущего времени.
В XV веке, вероятно, под польским влиянием появляется конструкция современного типа: буду + инфинитив. Однако конкуренцию у других глаголов она выигрывает лишь в XVIII веке, когда и становится нейтральным способом выражения будущего времени у глаголов несовершенного вида.
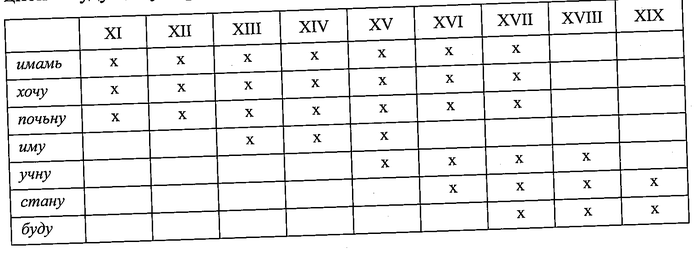
В таблице отражено распределение по векам вспомогательных глаголов, при помощи которых образовывались конструкции со значением будущего времени. Четвёртый выжил в украинском: робитиму «буду делать».
Ещё одна конструкция – так называемое будущее сложное II или предбудущее, буду дѣлалъ, которое могло обозначать действие в будущем, предшествующее другому действию в будущем, но также имело и ряд модальных значений. Эта конструкция в русском исчезает в XV-XVI веках, но, скажем, в польском и словенском это сейчас основной способ выражения будущего времени.
На рубеже XII-XIII в древнерусском начинает утрачиваться двойственное число. В XIII-XIV веках этот процесс доходит до логического завершения, что приводит к серьёзному сокращению количества глагольных форм.

В итоге в современном русском мы получаем следующую ситуацию:
- 3 лица;
- 2 числа;
- 3 времени;
- 2 залога;
- 3 наклонения;
- 3 рода.
Для глагола несовершенного вида это даёт 52 формы. Для совершенного меньше, 40, поскольку у глаголов совершенного вида нет настоящего времени. Однако если рассматривать видовую пару (делать – сделать) не как два глагола, а как один (а такой взгляд существует), то мы получаем 92 формы для одного глагола. Разумеется, точное количество зависит от массы деталей, например, я не учитываю инфинитив и формы императива типа пойдёмте, не учитываю причастия и род. В реальности формы пассивного залога от многих глаголов используются редко или не используются вовсе.
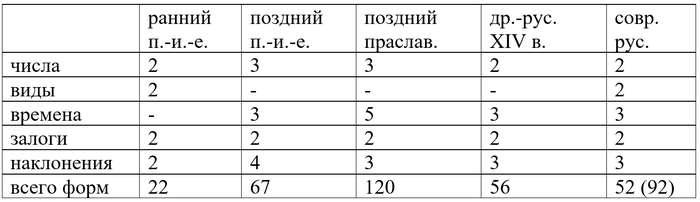
Вот так на пути от раннего праиндоевропейского возникло и исчезло двойственное число, исчез и возник вид, развилась и упростилась система прошедших времён, возникло, исчезло и снова возникло будущее время и так далее. Никаких далекоидущих выводов из этого, конечно, делать нельзя. Так, большое количество форм в позднем праславянском объясняется пассивным залогом, формы которого использовались редко, и двойственным числом.
Другие славянские языки обошлись с праславянским наследием иначе. Например, в болгарском глагол усложнился: не только сохранились все прошедшие времена, но и появились будущие, а также новое наклонение – пересказывательное. Зато в болгарском утрачен инфинитив и склонение существительных (но есть артикль). В словенском система времён упростилась подобно русской, но есть двойственное число и супин.
Если выйти за пределы славянских языков, то будет примерно то же: старые категории исчезали, а на их место приходили новые. Из этого абсолютно не следует, что языки деградировали, или наоборот, что они совершенствовались. Так что раньше было не лучше. Раньше было по-другому.
Литература:
Kapović M. Proto-Indo-European morphology // The Indo-European Languages. London, New York, 2017. Pp. 61-110.
Историческая грамматика русского языка: Энциклопедический словарь / Под ред. В.Б. Крысько. М., 2020.
В прошлом посте я упомянул о том, что сходство латинского habēre /хабéэрэ/ «иметь» и немецкого haben /хáабəн/ «иметь» случайно, и эти два глагола неродственны.
Читатели попросить рассказать об этом поподробнее:

Что ж, приступим. Начать следует с того, что в прагерманском, предке всех германских языков, произошло яркое фонетическое изменение, которое мы сейчас называем законом Гримма. В ходе этого изменения прагерманская система согласных подверглась серьёзной перестройке: например, старый к перешёл в х, а г – в к. Для лучшего понимания продемонстрирую это в виде таблицы (с очень большими упрощениями):
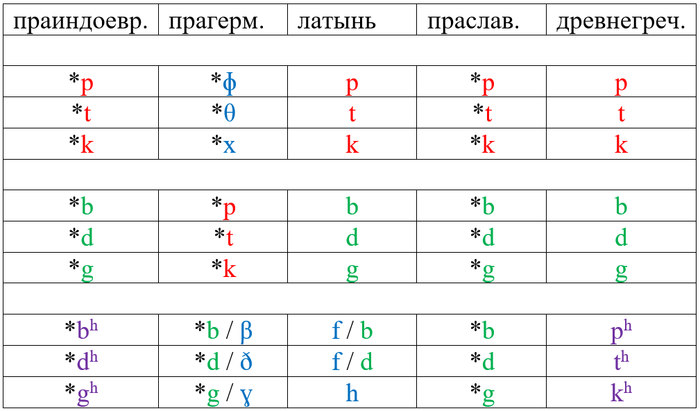
Комментарий к таблице: ɸ и β – это звуки, близкие к ф и в, но произносятся не губой и зубами, а двумя губами. θ и ð – как первые звуки в английских thin и this; x – как русский х; ɣ - как в слове город в южнорусских говорах. Символ ʰ обозначает придыхание.
В нашем случае это будет означать, что немецкому h в латыни соответствует не h, а c /к/. Приведу несколько примеров:
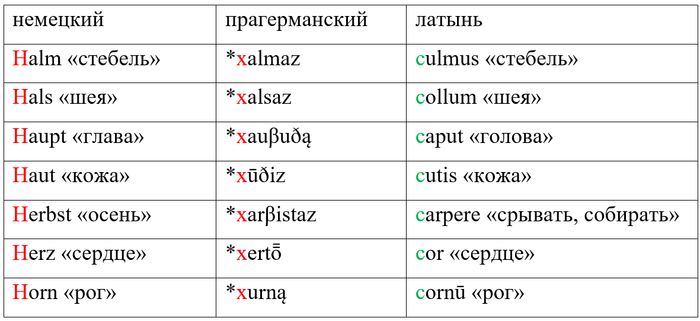
Комментарий: макрон над гласным обозначает долготу гласного; хвостик – носовость.
Идём дальше. Ещё одним важным фонетическим изменением в прагерманском является закон Вернера. В ходе него *ɸ, *θ, *x (для упрощения эти звуки чаще записывают как *f, *þ, *h) озвончились и перешли в *β, *ð, *ɣ, если гласный перед ними не был ударным.
Для нас это выливается в то, что в определённом положении немецкий b соответствует латинскому p. Несколько примеров:
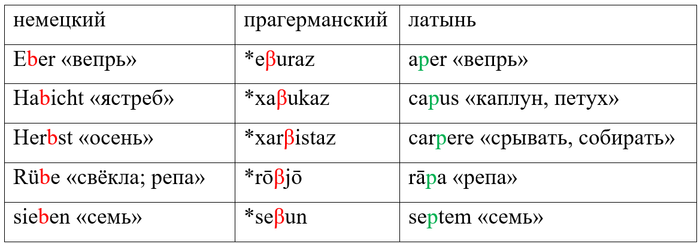
Таким образом, немецкое haben (а правильнее, прагерманское *xaβēną) не может быть родственником латинского habēre. В латыни мы бы ожидали корень вроде cap-. И такой корень в латыни действительно есть – это capere /кáпэрэ/«брать». Его потомком является, например, итальянское capire /капи́рэ/ «понимать».

А что насчёт значения? Ведь «брать» и «иметь» - это не одно и то же. Однако мы знаем пример именно такого развития семантики «взять» > «иметь». Это собственно наши русские глаголы взять и иметь (о том, как это возможно фонетически я рассказывал в отдельном посте).
Если вернуться к первой таблице, то станет понятно, что латинский h- происходит из *gʰ. Соответственно, habēre можно выводить от корня вроде *gʰab- или *gʰabʰ-. В связи с этим появилось предположение, что habēre родственно немецкому geben «давать» (прагерманское *gebaną). Но тут, к сожалению, не сходятся гласные этих корней.
Зато потенциальный родственник латинского глагола есть в славянских языках, например, в восточнославянских диалектах: габáць «хватать» в белорусских, гáбати «хватать» в украинских, габáться «бороться» в русских.
Теперь упорядочу вышеописанное в виде схемы:
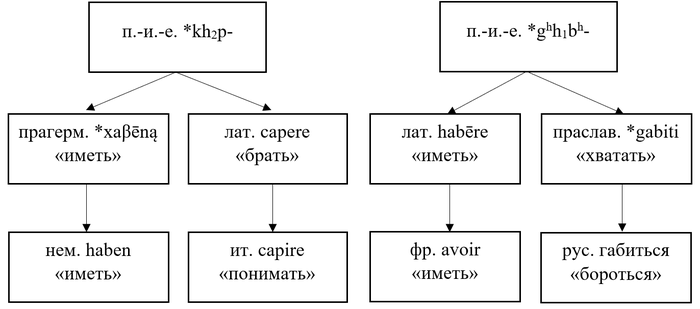
Разобранный мною пример учит нас, что просто сходство двух слов ещё ни о чём не говорит. Чтобы доказать родство, нужно уложить эти слова в прокрустово ложе регулярных фонетических соответствий.
Кстати, закон Гримма объясняет и другой пример из прошлого поста: французское feu /фё/ «огонь» – немецкое Feuer /фóйа/ «огонь» не могут быть родственниками. Собственно, уже даже между feu и английским fire сходство невелико. Вот Feuer и fire – действительно родственники, они – потомки прагерманского *ɸōr «огонь». Как мы помним, германскому ɸ соответствует p в других языках, и родственника *ɸōr найти несложно, это древнегреческое πῦρ /пюур/ «огонь» (отсюда пироман, пиротехника и пиролиз).
А французское feu вместе с итальянским fuoco «огонь» и испанским fuego «огонь» - потомки латинского слова focus «очаг; жар, огонь».
Регулярно сталкиваюсь в Интернете с одной и той же ошибкой. Человек, увидев два похожих слова в разных языках, спешит считать, что между ними есть какая-то взаимосвязь. Например, русская херня и латинская hernia /хэ́рниа/ «грыжа», русская берлога и немецкий Bär.
На самом деле, сходство может быть вызвано тремя причинами:
а) родство;
б) заимствование;
в) случайное совпадение.
Люди склонны недооценивать третий вариант. Что поделать, так уж мы устроены.
На самом деле, фонем (сущностей, которые носители языка считают одним звуком) в языках не так уж много: обычно несколько десятков, в среднем, 30-40. Например, в гавайском всего 8 согласных, 10 простых гласных и 15 дифтонгов. При этом, в гавайском существуют строгие ограничения на структуру слога: допустимы только слоги вида V или CV (где V - любой гласный, а C – любой согласный). Несложно подсчитать, что теоретически в гавайском может быть лишь 208 возможных слогов.
В русском слогов намного больше, однако в действительности используются далеко не все возможности. Потенциально у нас могут быть слоги щвяк, хлазр, чнюмс и так далее, но на практике они не встречаются. Кроме того, одни звуки встречаются чаще, другие реже. Например, р и а – звуки частотные, поэтому совершенно не удивительно, что Задорнову удалось отыскать своего Ра в куче русских слов. Уже Нун найти гораздо сложнее.
Всё это приводит к тому, что в любой случайно взятой паре языков всегда можно найти фонетически похожие слова. Другое дело, что чаще всего у них будет серьёзно отличаться значение. Например, английское bread и русское бред звучат довольно схоже, но любому понятно, что делать на основании этого какие-либо выводы об их родстве – бред.
Но иногда бывает, что по воле случая схожим оказывается не только форма, но и значение.
В качестве примера возьмём японский. Это язык с долгой письменной традицией, длительное время находившийся в стороне от европейского мира. Вдобавок большинство европейских заимствований в японском записывается особым слоговым письмом – катаканой (впрочем, есть исключения). Это позволяет сравнительно легко определить, пришло ли какое-либо слово в японский из европейских языков или нет. Кроме того, у японского довольно бедная фонетика с серьёзными ограничениями на структуру слога, что должно повышать вероятность случайного совпадения.
Закрыв глаза на небольшие фонетические и семантические расхождения, можно обнаружить ряд интересных примеров:
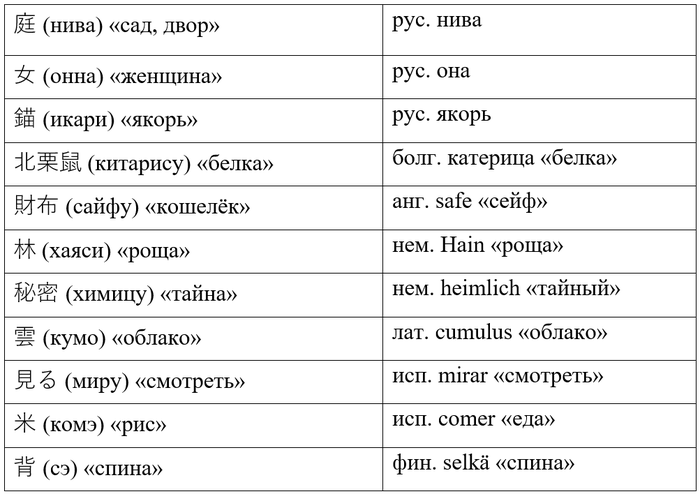
В некоторых случаях сходство просто поразительно, как в первом примере, допустим. Капля фантазии, и вот уже заброшенные в Японию штормом русские моряки учат японцев пахать, а поскольку земли в Японии мало, то пахать приходилось прямо во дворе. Вот только в древнеяпонском слово 庭 звучало не как нива, а как нипа. И сравнивать его следует не с русским словом, а с корейским 납작 /напчак/ «плоский».
Возьмём второй пример, русское она и японское онна «женщина». И в этом случае случайность сходства станет очевидной, если знать, что в древнеяпонском 女 звучало как /вомина/. Что, кстати, похоже уже на английское woman.
Ну ладно, нива и онна – слова короткие, совпадение особо никого не удивит. Но вот болгарская и японская белки – точно сёстры: катерица и китарису. Да и пишут это слово японцы не только иероглифами, но и катаканой: キタリス. Однако кита в китарису означает «север, северный», и на самом деле китарису обозначает белку обыкновенную (то есть для японцев северную), а общее название для всех белок, как несложно догадаться, рису.
Поэтому лингвисты не опираются на несколько случайно выбранных пар слов, а пытаются отыскать между языками регулярные фонетические соответствия (подробнее в этом посте). На их основании устанавливаются фонетические изменения и реконструируются праязыки.
Поскольку мы знаем, что испанский является потомком латыни, а японский – древнеяпонского, не очень осмысленно сравнивать формы современных испанского и японского. Лучше взять как раз латынь и древнеяпонский. А ещё лучше праиндоевропейский, к которому восходит латынь, и праалтайский, предок древнеяпонского.
Таким образом, если мы захотим доказать родство слов из таблицы, нам нужно будет учесть фонетические (и не только) изменения на всех промежуточных стадиях между ними, пока не придём к их гипотетическому общему предку, праностратическому языку.
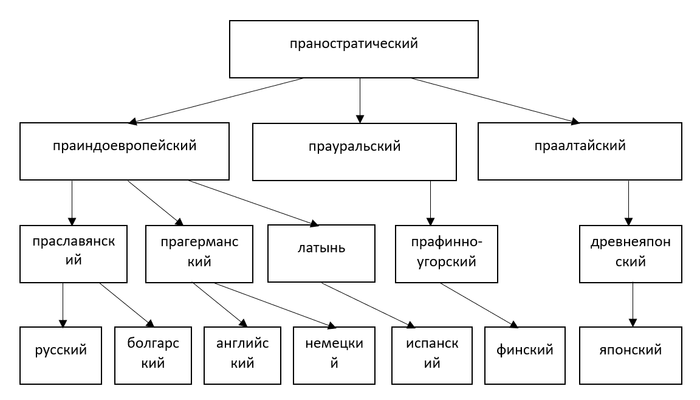
Если же не следовать строгой процедуре, то в любой произвольно взятой паре языков мира окажется несколько поразительно похожих, но неродственных слов. Классические примеры:
латинское habere /хабéэрэ/ «иметь» – немецкое haben /хáабəн/ «иметь»;
латинское deus /дэус/ «бог» – древнегреческое θεός /т˟эóс/ «бог»;
французское feu /фё/ «огонь» – немецкое Feuer /фóйа/ «огонь»;
французское temp /тã/ «время» – английское time /тайм/ «время»;
английское much /мач/ «много» – испанское mucho /мýчо/ «много»;
английское bad /бэд/ «плохой» – персидское بد /бэд/ «плохой».
И наконец мои личные фавориты: итальянское poltrona /полтрóна/ «кресло» и русское «полтрона».
Предыдущие посты на тему:
Как работает историческая лингвистика, или почему не доставляет Ра
Продолжаю разбирать причуды и нелогичности английской орфографии. В древнеанглийской версии латинского алфавита было несколько специфических букв. Остановимся на двух из них (выделены красным):
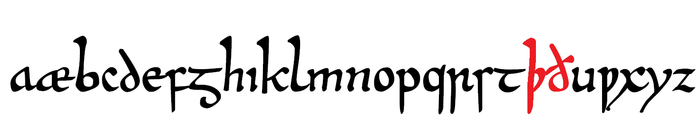
Буква þ (thorn) пришла из рунического алфавита, а ð (that, eth или edh) – это модифицированное d. Обе использовались для обозначения особых звуков (глухого и звонкого) как в современных словах thin и this, в зависимости от места и времени создания рукописи писцы отдавали предпочтение одной или другой букве или же использовали обе как взаимозаменяемые.
После нормандского завоевания под влиянием французской орфографии англичане обзавелись рядом диграфов со вторым элементом h: ch, sh, gh, wh и th. Последний включился в конкурентную борьбу между þ и ð.
В XIII веке ð исчезла с листов рукописей, а в следующем веке и þ уступила натиску th, и вместо þe и þin стали писать the и thin. В своих поздних версиях þ писалась довольно похоже на y, и в XIX веке þe из старых рукописей было ошибочно прочитано как ye, что привело к появлению псевдоархаичного ye вместо the на некоторых вывесках.

Вторую жизнь буква ð обрела в рамках Международного фонетического алфавита. В нём она обозначает звонкий звук, как в слове this /ðɪs/. Глухой обозначается греческой тетой: thin /θɪn/.
Закономерен вопрос, почему англичане обозначали два звука одной буквой. Как я уже упоминал в посте о лорде, в древнеанглийском были звуки f и v. Однако они находились в положении дополнительного распределения: звонкий v мог находиться только после ударного гласного (опционально прикрытого согласным r, l, n или m) и перед безударным. Во всех остальных случаях выступал только глухой f. Соответственно носителями языка эти два звука воспринимались как два варианта одной сущности (такую сущность мы называем фонемой, а «варианты» – аллофонами). Так же ситуация выглядела и для пар s/z и θ/ð.
В среднеанглийский период в силу некоторых процессов ситуация изменилась, и в современном английском θ и ð – это разные фонемы. Можно подобрать и минимальные пары: wreath /ɹiːθ/ «венок» – wreathe /ɹiːð/ «обвивать»; thigh /θaɪ/ «бедро» – thy /ðaɪ/ «твой». Тем не менее, орфография сохранила обозначение как θ, так и ð при помощи th. Была попытка ввести обозначение dh для ð, но она не прижилась.
Иногда θ и ð чередуются в родственных словах, что, конечно, является наследием древнеанглийского. Помимо wreath – wreathe можно назвать ещё несколько примеров: breath /breθ/ «дыхание» – breathe /briːð/ «дышать»; bath /bɑːθ/ «ванна» – bathe /beɪð/ «купаться»; south /saʊθ/ «юг» – southern /ˈsɐðən/ «южный»; north /nɔːθ/ – northern /ˈnɔːðən/, worth /wɜːθ/ «достоинство» – worthy /'wɜːðɪ/ «достойный».
Теоретически получается, что если в древнеанглийском ð выступал после гласного, то мы бы ожидали, что в современном английском не будет слов, начинающихся на этот согласный. На практике же они встречаются: than /ðæn/ «чем», that /ðæt/ «тот», определённый артикль the /ðiː/ ~ /ðɪ/ ~ /ðə/, then /ðen/ «тогда», there /ðɛə/ «там», they /ðeɪ/ «они», this /ðɪs/ «этот», thou /ðaʊ/ «ты», though /ðəʊ/ «хотя» и ряд других. Однако если мы присмотримся к этим словам, то обнаружим, что это местоимения, наречия, союзы и так далее. В предложении эти слова выступали как безударные, и получалось, что если, например, артикль the попадал в позицию после ударного гласного (John the Good), то звучал как /ðə/, а после безударного – как /θə/. Со временем это распределение разрушилось, и был обобщён (то есть стал использоваться вне зависимости от позиции) вариант со звонким согласным.
В эпоху Возрождения во время распространения так называемых «этимологизирующих» написаний (см. отдельный пост) диграф th вводился на место старого t, если английское слово происходило от греческого слова с θ:

Случалось, что менялось не только написание, но и произношение, как в throne /θɹəun/ «трон» (в среднеанглийском было trōne), orthography /ɔːˈθɒgɹəfɪ/ «орфография» (в среднеанглийском – ortografie) или имени Catherine /ˈkæθəɹɪn/ (старое произношение сохранилось в уменьшительном Kate /keɪt/).
Есть случаи, когда h вводилось в написание ошибочно, например в случаях Anthony /ˈæntənɪ/ или Thames /temz/ «Темза». И здесь это иногда приводило к изменению произношения: anthem /ˈænθəm/ «гимн», author [ˈɔːθə] «автор». Американцы здесь пошли дальше, чем англичане, они произносят Anthony [ˈænθənɪ] и Thames [θemz] (когда речь о реке в Коннектикуте).
Особняком стоят словосложения, где первая часть заканчивается на -t, а вторая начинается на h-. Например: courthouse /ˈkɔːthaus/ «здание суда», penthouse /ˈpenthaus/ «пентхаус». В географических названиях на -ham (которое этимологически идентично слову home) -h- обычно не читается: Birmingham /ˈbɜːmɪŋəm/ «Бирмингем», Nottingham /ˈnɒtɪŋəm/ «Ноттингем», Oldham /ˈəuldəm/ «Олдем». То же и в случае топонимов Gotham /ˈɡəutəm/ (английской деревни, не малой родины Бэтмена), Waltham /ˈwɔːltəm/. А вот Statham /ˈsteɪθəm/, Northampton /nɔːˈθæmptən/ и Southampton /sauˈθæmptən/ произносятся через -θ-, поскольку в них изначально было сочетание -θ-h-, а не -t-h-.
Итак, резюмируем:
1. В древнеанглийском были звуки θ (глухой) и ð (звонкий). Поскольку они не могли находиться в одной и той же позиции в слове, носители языка воспринимали их как два варианта одного и того же звука и, соответственно, обозначали одной буквой – þ или ð.
2. После нормандского завоевания англичане стали активно использовать диграфы со вторым элементом h, и на смену þ или ð пришло сочетание th.
3. В среднеанглийский период ситуация изменилась, и θ и ð стали осознаваться как разные звуки. Однако в орфографии это никак не отразилось, оба звука по-прежнему обозначаются при помощи th.
4. В эпоху Возрождения th стали вводить на место t, если считалось, что слово греческого происхождения. В связи с этим есть случаи, когда пишется th, но читается /t/. В некоторых книжных словах это привело к изменению и произношения с /t/ на /θ/.
5. Особый случай представляют словосложения, в них th может читаться как th, t или θ, в зависимости от этимологии.Источники:
Algeo J. The Origins and Development of the English Language. Boston, 2010. Pp. 142-143.
Millward C., Hayes M. A Biography of the English Language. Boston, 2012. P. 248.
Smith J. Sound Change and the History of English. Oxford, 2007. Pp. 57-58.
The Cambridge History of the English Language, Vol. 2. 1066-1476. Cambridge, 2006. Pp. 36, 58-60.
Предыдущие посты цикла:
Почему английская орфография такая странная: gh
Почему английская орфография такая странная-2: island
Почему английская орфография такая странная-3: -tion
Почему английская орфография такая странная-4: love
Почему английская орфография такая странная-5: wh
Почему английская орфография такая странная-6: ch, ph, sh, zh, kh
По просьбе @arsdor начинаю цикл постов по «экономической» этимологии. Сегодня поговорим о том, связан ли глагол платить со словами платок и платье.
Родственники нашего платить есть во всех славянских языках, и для праславянского состояния уверенно восстанавливается форма *platiti.

Так что полторы тысячи лет назад славянам вполне были известны товарно-денежные отношения. Другое дело, что собственных монет они тогда ещё не чеканили, а в качестве платёжного средства выступали не только драгоценные металлы, но и, например, шкурки пушного зверя. Неслучайно хорватская валюта называется куной (и так же называли мелкую монету в древней Руси).

Путешественник Ибрагим ибн Якуб, живший в X веке, сообщает, что чехи использовали в качестве денег платки:
И делаются в странах Бвймы легкие платочки, весьма тонкой ткани на подобие сеток, которые ни к чему не годятся. Цена их у них постоянно кншар за десяток платков. Ими они торгуют и рассчитываются друг с другом; они имеют (целые) сосуды их и они считаются богатством у них и ценнейшими вещами; ими покупается пшеница и мука и лошади и золото и серебро и всякие вещи.
Это и другие свидетельства навели этимологов на мысль о родстве *platiti и *platъ «кусок ткани». Среди потомков последнего, например, древнерусское платъ «лоскут, кусок ткани; платок».
Так, Кирик спрашивает, можно ли попу вести службу в одежде, в которую был вшит женский платок:
Аще слоучить(с҃) платъ женьскыи въ портъ въшити попоу достоит ли въ томь слоу(ж҃)ти портѣВ современном литературном русском плат почти не используется (но у Блока: «да плат узорный до бровей»), его вытеснило уменьшительное – платок.
От платъ образовано также слово платье, которое сейчас обозначает женскую одежду, но ещё в XIX веке вполне себе распространялось и на мужскую.
Раньше существовало и производное с другим суффиксом – платище «отрез ткани». Например, у Афанасия Никитина:
А иные наги всѣ, одно платище на гузне.
Ещё один дериват от плат – заплата, заплатка. Так что сходство зарплаты и заплаты неслучайно (а разница, как известно, в том, что заплата больше дыры, а зарплата меньше).
А вот платина является заимствованием из испанского, в котором platina – уменьшительное от plata «серебро».
Сведём всё это в схему (для простоты буду использовать только современные русские формы):


