Главная ошибка лингвофриков
Регулярно сталкиваюсь в Интернете с одной и той же ошибкой. Человек, увидев два похожих слова в разных языках, спешит считать, что между ними есть какая-то взаимосвязь. Например, русская херня и латинская hernia /хэ́рниа/ «грыжа», русская берлога и немецкий Bär.
На самом деле, сходство может быть вызвано тремя причинами:
а) родство;
б) заимствование;
в) случайное совпадение.
Люди склонны недооценивать третий вариант. Что поделать, так уж мы устроены.
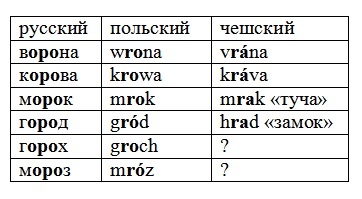
На самом деле, фонем (сущностей, которые носители языка считают одним звуком) в языках не так уж много: обычно несколько десятков, в среднем, 30-40. Например, в гавайском всего 8 согласных, 10 простых гласных и 15 дифтонгов. При этом, в гавайском существуют строгие ограничения на структуру слога: допустимы только слоги вида V или CV (где V - любой гласный, а C – любой согласный). Несложно подсчитать, что теоретически в гавайском может быть лишь 208 возможных слогов.
В русском слогов намного больше, однако в действительности используются далеко не все возможности. Потенциально у нас могут быть слоги щвяк, хлазр, чнюмс и так далее, но на практике они не встречаются. Кроме того, одни звуки встречаются чаще, другие реже. Например, р и а – звуки частотные, поэтому совершенно не удивительно, что Задорнову удалось отыскать своего Ра в куче русских слов. Уже Нун найти гораздо сложнее.
Всё это приводит к тому, что в любой случайно взятой паре языков всегда можно найти фонетически похожие слова. Другое дело, что чаще всего у них будет серьёзно отличаться значение. Например, английское bread и русское бред звучат довольно схоже, но любому понятно, что делать на основании этого какие-либо выводы об их родстве – бред.
Но иногда бывает, что по воле случая схожим оказывается не только форма, но и значение.
В качестве примера возьмём японский. Это язык с долгой письменной традицией, длительное время находившийся в стороне от европейского мира. Вдобавок большинство европейских заимствований в японском записывается особым слоговым письмом – катаканой (впрочем, есть исключения). Это позволяет сравнительно легко определить, пришло ли какое-либо слово в японский из европейских языков или нет. Кроме того, у японского довольно бедная фонетика с серьёзными ограничениями на структуру слога, что должно повышать вероятность случайного совпадения.
Закрыв глаза на небольшие фонетические и семантические расхождения, можно обнаружить ряд интересных примеров:
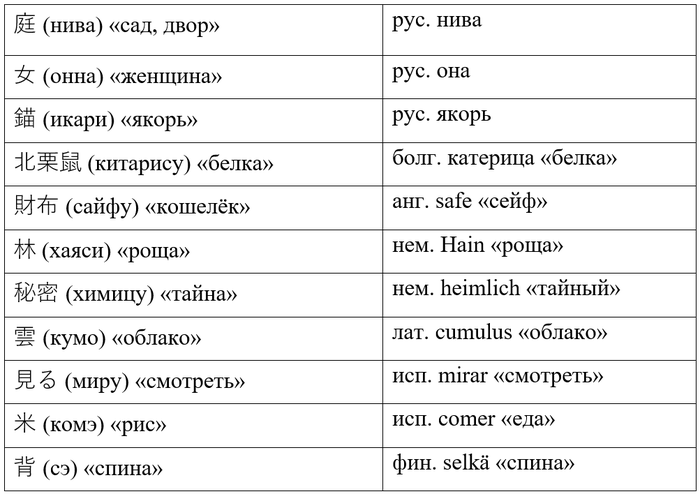
В некоторых случаях сходство просто поразительно, как в первом примере, допустим. Капля фантазии, и вот уже заброшенные в Японию штормом русские моряки учат японцев пахать, а поскольку земли в Японии мало, то пахать приходилось прямо во дворе. Вот только в древнеяпонском слово 庭 звучало не как нива, а как нипа. И сравнивать его следует не с русским словом, а с корейским 납작 /напчак/ «плоский».
Возьмём второй пример, русское она и японское онна «женщина». И в этом случае случайность сходства станет очевидной, если знать, что в древнеяпонском 女 звучало как /вомина/. Что, кстати, похоже уже на английское woman.
Ну ладно, нива и онна – слова короткие, совпадение особо никого не удивит. Но вот болгарская и японская белки – точно сёстры: катерица и китарису. Да и пишут это слово японцы не только иероглифами, но и катаканой: キタリス. Однако кита в китарису означает «север, северный», и на самом деле китарису обозначает белку обыкновенную (то есть для японцев северную), а общее название для всех белок, как несложно догадаться, рису.
Поэтому лингвисты не опираются на несколько случайно выбранных пар слов, а пытаются отыскать между языками регулярные фонетические соответствия (подробнее в этом посте). На их основании устанавливаются фонетические изменения и реконструируются праязыки.
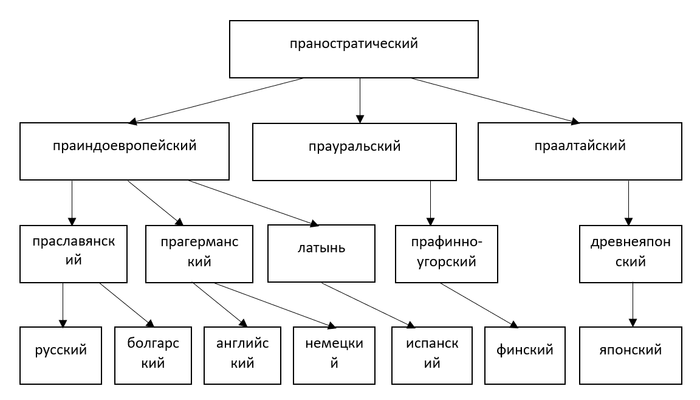
Поскольку мы знаем, что испанский является потомком латыни, а японский – древнеяпонского, не очень осмысленно сравнивать формы современных испанского и японского. Лучше взять как раз латынь и древнеяпонский. А ещё лучше праиндоевропейский, к которому восходит латынь, и праалтайский, предок древнеяпонского.
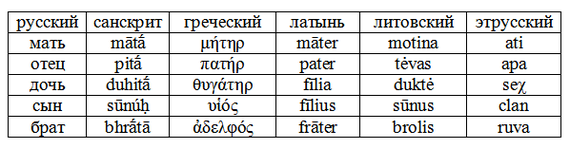
Таким образом, если мы захотим доказать родство слов из таблицы, нам нужно будет учесть фонетические (и не только) изменения на всех промежуточных стадиях между ними, пока не придём к их гипотетическому общему предку, праностратическому языку.
Если же не следовать строгой процедуре, то в любой произвольно взятой паре языков мира окажется несколько поразительно похожих, но неродственных слов. Классические примеры:
латинское habere /хабéэрэ/ «иметь» – немецкое haben /хáабəн/ «иметь»;
латинское deus /дэус/ «бог» – древнегреческое θεός /т˟эóс/ «бог»;
французское feu /фё/ «огонь» – немецкое Feuer /фóйа/ «огонь»;
французское temp /тã/ «время» – английское time /тайм/ «время»;
английское much /мач/ «много» – испанское mucho /мýчо/ «много»;
английское bad /бэд/ «плохой» – персидское بد /бэд/ «плохой».
И наконец мои личные фавориты: итальянское poltrona /полтрóна/ «кресло» и русское «полтрона».
Предыдущие посты на тему:
Как работает историческая лингвистика, или почему не доставляет Ра