Состояние индустрии разработки от JetBrains 2024
С 2017 года JetBrains проводит опросы, на базе которых готовит отчёты о состоянии индустрии. В 2024 году опросили 23к разработчиков. В отчёте есть разное интересное, имеет смысл ознакомиться с ним целиком. Мы же с вами посмотрим на отдельные моменты, которые я считаю самыми примечательными.
В топе языков всё стабильно, там JavaScript, Python, Java. Впервые Go обогнал PHP, последний уже довольно давно увядает.
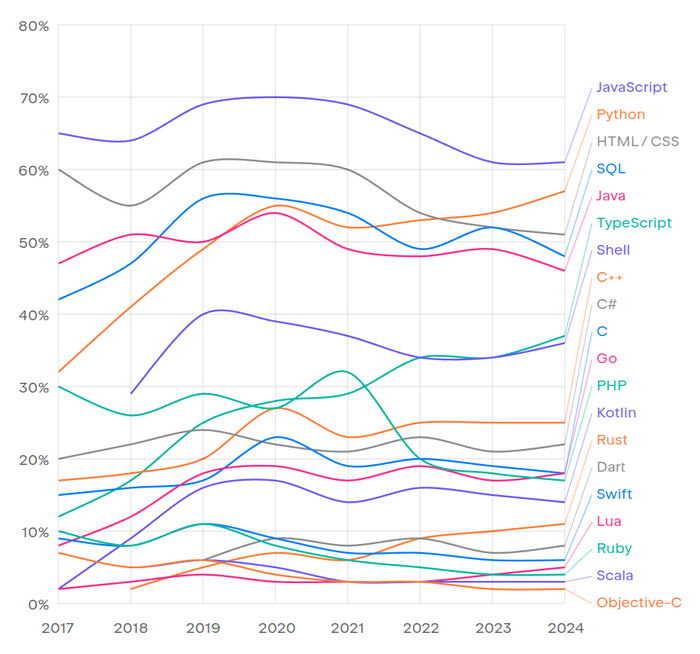
Да, я знаю, что HTML не язык программирования. И SQL я бы сюда не включал. Но кто я, а что JetBrains?
Интересен блок с планами. Для каждого языка можно выбрать "мой основной язык" или "планирую использовать". Основной язык Python у 35% разработчиков, ещё 6% планируют его использовать. Самые большие планы на внедрение у Go (10%) и Rust (11%). Интересно, реализуется ли это.
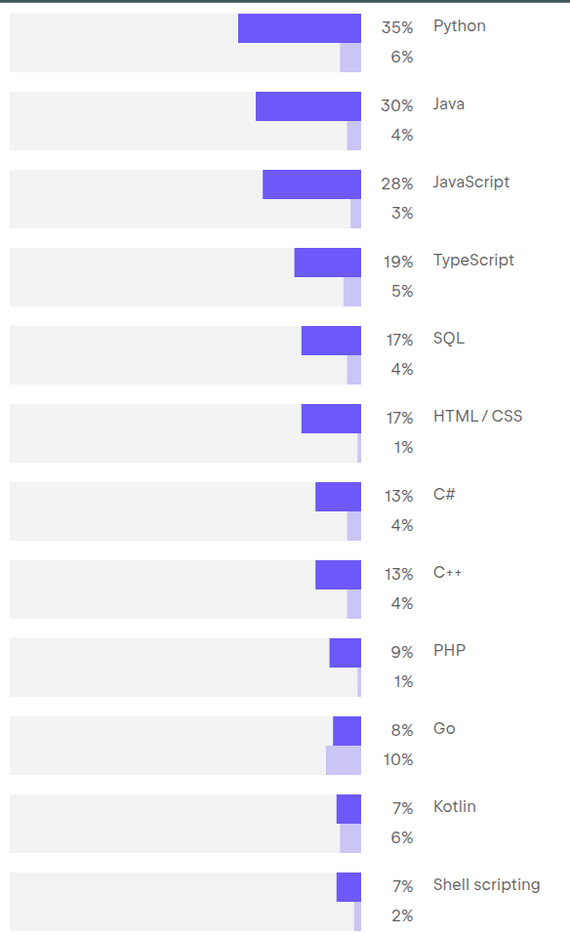
Даже у Shell 2%. Никто не планирует писать на PHP
На рынке РФ вроде Rust не очень востребован, и число вакансий это пока подтверждают.
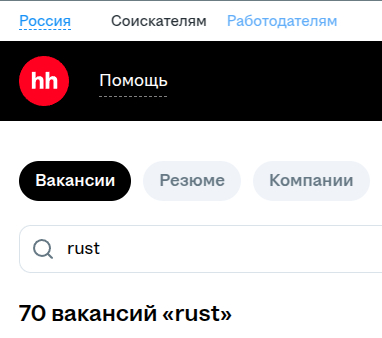
По России вакансий Rust кот наплакал
Компания JetBrains попробовала вывести некий "индекс перспективности" языка. Сомневаюсь, что на него разумно опираться при выборе инструмента, но пусть будет
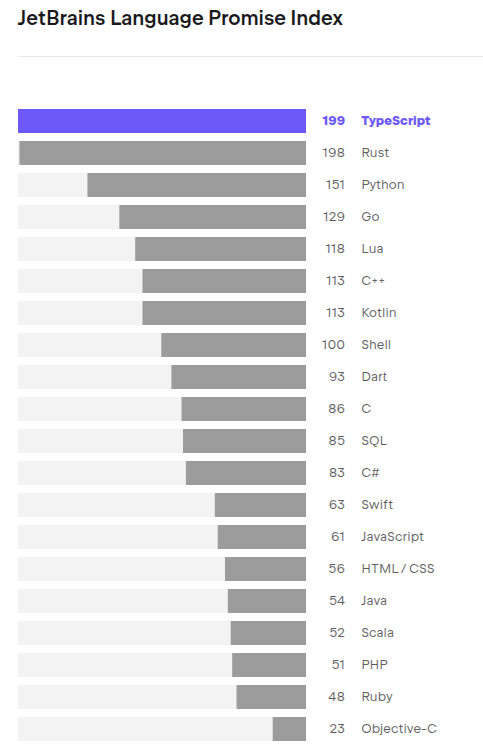
Promise Index языков
Интерес может представлять такая двумерная табличка. Справа указаны сферы деятельности (разработка веб-сайтов, веб-сервисов, ...), вверху язык. На пересечении указан процент людей, которые указали основным язык в этой сфере.
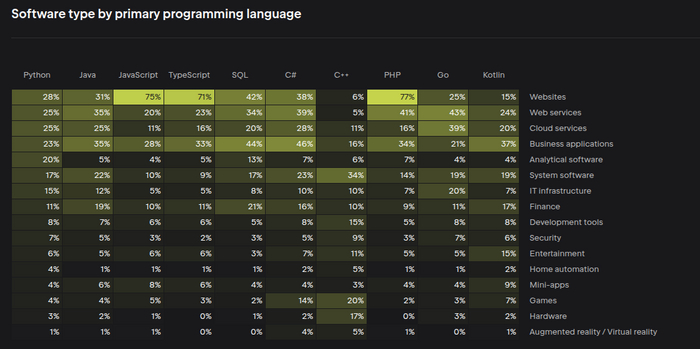
Я бы на эту табличку смотрел так. Если интересна некая индустрия, можно посмотреть, какие технологии там на коне. Правда, по этой логике надо на PHP сайты писать, чего вам делать не рекомендую — см. выше про увядание этого языка
В топе баз данных тоже всё стабильно: MySQL, PostgreSQL, MongoDB, SQLite, Redis. Приятно, что ClickHouse от Яндекса потихоньку растёт. Странно, что Elasticsearch впервые в этом году добавили в опрос.
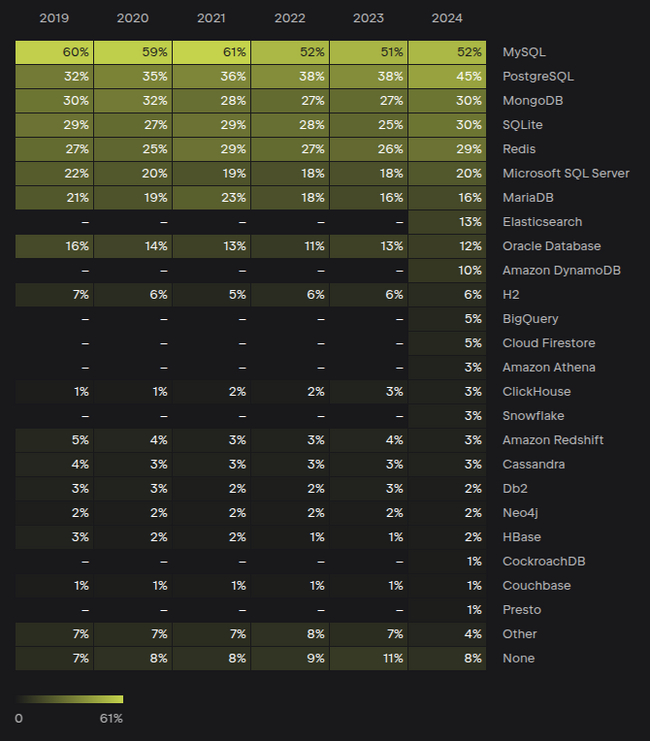
Связка PostgreSQL + MongoDB + Elasticsearch топ. Не является инвестиционной рекомендацией
Дальше моё любимое. Не использует виртуализацию 25% респондентов. 50% с докером, дальше есть нюансы.
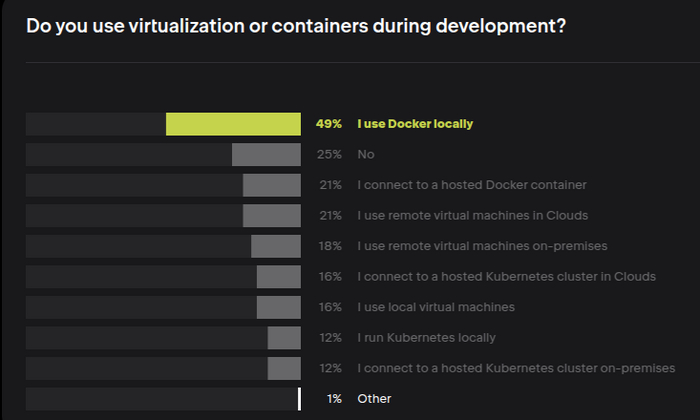
Удивлён, что докера не 90%
Проникновение искусственного интеллекта в разработку довольно сильное. 70% пробовали, а 50% постоянно используют ChatGPT. Можно позалипать на цифры постоянного использования у других игроков: 26% у GitHub Copilot, 7% Google Gemini, 5% JetBrains AI, 3% Anthropic, 1% Tabnine, 2% локальный AI, 3% Codeium, 1% Blackbox AI. 1% Llama, 1% Gemini, 1% Cursor. Есть куда расти. Про остальных игроков я не слышал.
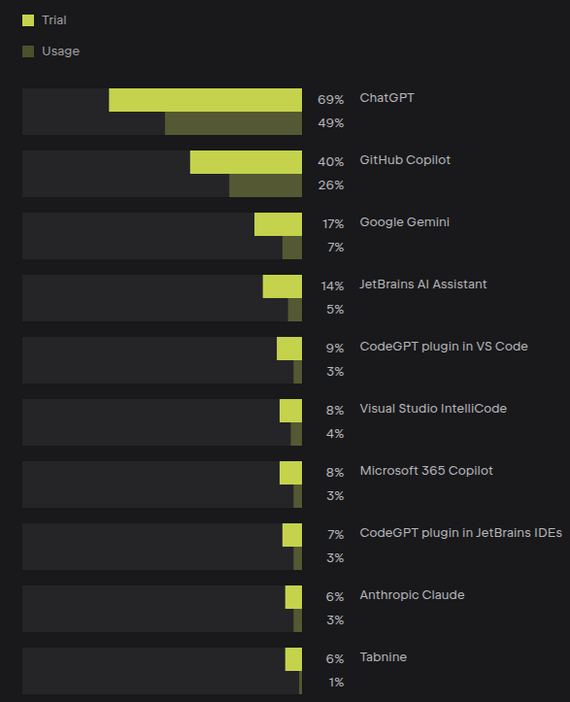
Странно, что GitHub Copilot (который по факту принадлежит Microsoft) отличается от Microsoft 365 Copilot. Или я не шарю?
Занятная статистика по профиту от ИИ. Теперь ИИ является не только чатботом, но и заменой поисковику, помощником кодера, автоматизатором рутинных задач. Интересно, а есть ли уже бот, который code review в MR проводит? Если кто такое видел или использовал, поделитесь впечатлениями.

Мы-то знаем, что 2% Other — это правило 34
В блоке Developers' Life интересная статистика про затраты времени на код и на коммуникацию (созвоны, чаты, почта). Вроде опрос разработчиков, но 5% ребят тратят на код меньше 20% времени. Пикабу читают, наверное.
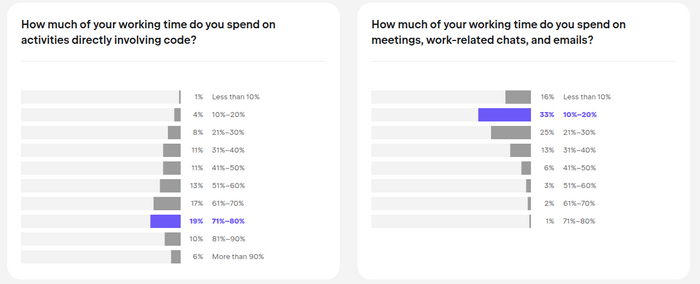
Слева затраты на код, справа на коммуникации
76% разработчиков изначально в ИТ, и 22% перешли в ИТ откуда-то. Мне был бы интересен срез по годам. В 2023 году картина была аналогичной, а дальше копать лень.
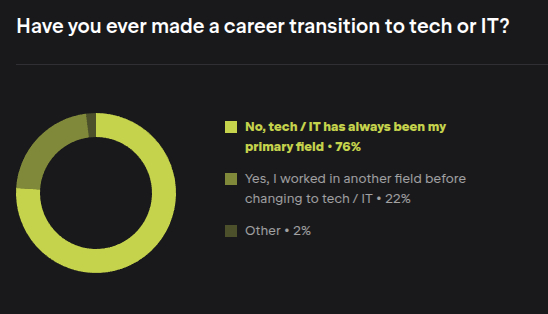
22% вкатунов. Хотя чёрт его знает, что значит another field
Интересен вопрос "самая сложная часть вашей работы". 38% отмечают понимание потребностей пользователей, 34% коммуникацию с командой (и ещё 16% с другими разработчиками). Проблема 32% в разборе чужого кода, и у 16% проблема в отладке. Непосредственно в написании кода сложности только у 15%, и в первую очередь эту часть сможет взять на себя ИИ. Остальные сложности, вероятно, пока останутся. А вообще всё выше подводит нас к важности софт скиллов, и об этом мы стали чаще писать статьи (например, как папки в телеграм для разработчика удобно настроить).
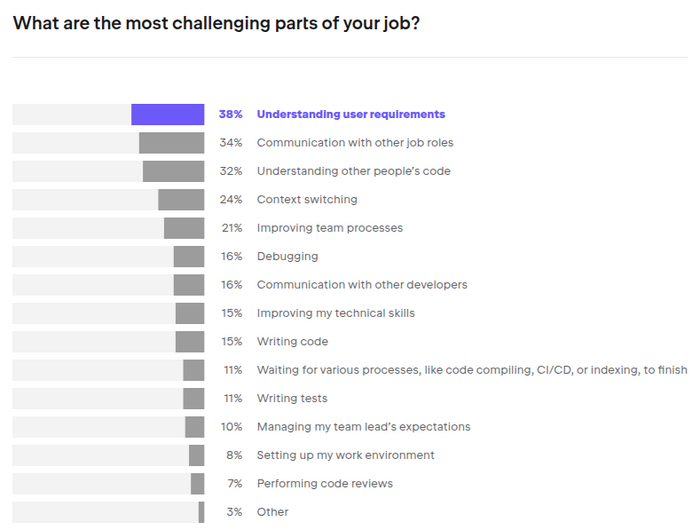
Жалкие 15% проблем в написании кода
Остальное время код компилируется, как известно

«Эй, ты воруешь ЖК‐мониторы?» — «Да, но я делаю это, пока мой код компилируется».
Иронично, что при этом 50% разработчиков работают в команде всего лишь из 2-7 человек. Одиночек и ещё 8%. И даже им сложно с коммуникацией, бедные команды по 10+ человек
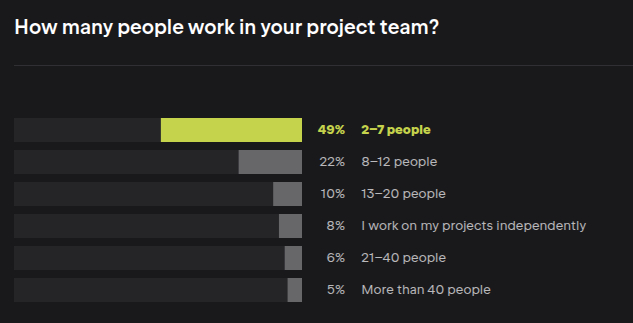
А виртуальные личности считаются в составе команды?
Почему-то в обзоре 2024 года этого вопроса нет, поэтому вот вам картинка из 2023. На какой операционной системе вы программируете?
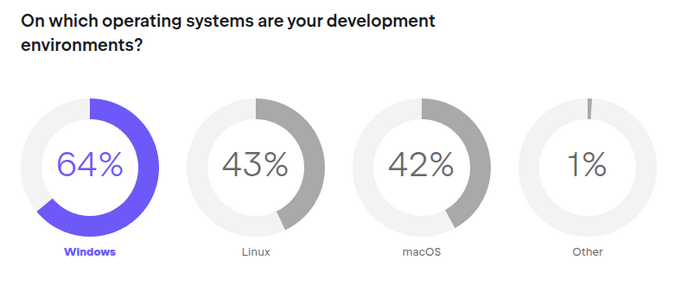
43% линукса. И ещё 42% тоже линукса, но на макбуках
Такое вот моё мнение об обзоре индустрии. Что вам запомнилось, а я это пропустил?
В DevFM пишу о полезном для разработчика: о базах данных, об архитектурных схемах, записываю видео по FastAPI + Docker для начинающих. А ещё у нас есть бесплатный курс cli-for-dev по Linux на степике.