



Рефакторим простое на python
Давайте посмотрим на 10 строк кода.
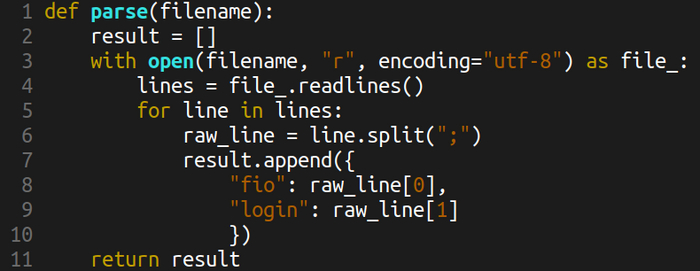
Вроде всё хорошо. Классическое открытие файла с помощью контекстного менеджера with, классическая построчная обработка. Разбиваем строку, записываем в список словарей. Всё ли по канону? Неа:
1. Смотрим документацию: readlines возвращает список всех строк файла. Значит, для большого файла может быть беда. Современный питон позволяет итерироваться сразу по объекту file_. Просто пишем
for line in file_:
2. raw_line[0] и прочие индексы — это всегда ужас. Заменяем на
fio, login = line.split(";")
Вроде то же самое, но мы сразу понимаем, что было в строке. И тут же видим следующую проблему.
3. А что, если в строке нет двоеточия, или этих двоеточий больше одного? То есть нужна обработка ошибок на исключение ValueError, если справа split вернул не два значения. Добавляем try-except.
4. Частая проблема split — это лишние пробелы. Скорее всего, потребуется strip всем переменным после split.
Итого 4 ошибки на 10 строк кода.
Теперь посмотрим на переработанный код. Docstring вырезан для краткости.
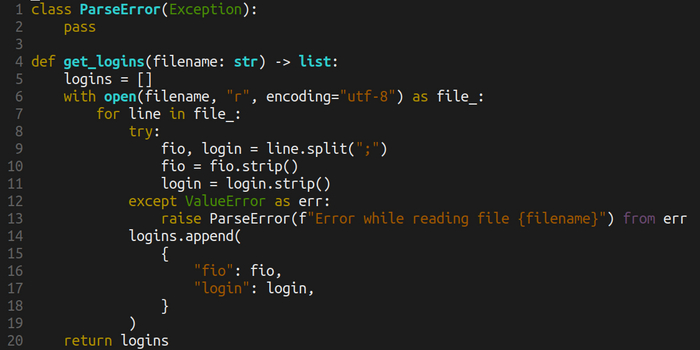
Код теперь крут:
1. Есть аннотация типов. Понятно, что на входе строка, на выходе список.
2. С файлом всё работаем через контекстный менеджер, то есть закрыть не забудем — оно само
3. Не забыли про запрет использования file как ключевого слова, поэтому file_
4. При разбиении строки по точке с запятой используем именованные переменные
5. При ошибках — кастомные исключения. Не забудьте их документировать в docstring
6. Добавлены strip для убирания лишних пробелов по краям. Опционально
7. Выходная переменная называется logins
8. При добавлении элемента в список мы на последнем элементе добавили запятую, чтобы при расширении словаря не ловить ошибку.
В общем, каждая строка на своём месте. Или всё ещё нет?
Возьмём такой входной файл
Иванов Иван;anetto
Сидоров Петр;bnetto
Петров Артём;сnetto
Для него вывод итогового logins будет выглядеть так
[{'fio': 'Иванов Иван', 'login': 'anetto'}, {'fio': 'Сидоров Петр', 'login': 'bnetto'}, {'fio': 'Петров Артём', 'login': 'сnetto'}]
Этот словарь не является удобной конструкцией, ФИО доступно как logins["fio"]. Кроме того, мы демонстрируем наружу внутреннее представление, нарушая принцип инкапсуляции. Замена словаря на список, например, заставит переписать весь код, который использует эту структуру данных. Какой может быть выход?
Создадим класс Student и превратим словарь в экземпляр класса. Можно использовать namedtuple из collections, но мы пойдём своим путём - создадим класс с двумя полями (fio, login) и двумя методами (конструктор и repr для вывода). Теперь logins будет списком экземпляров класса.
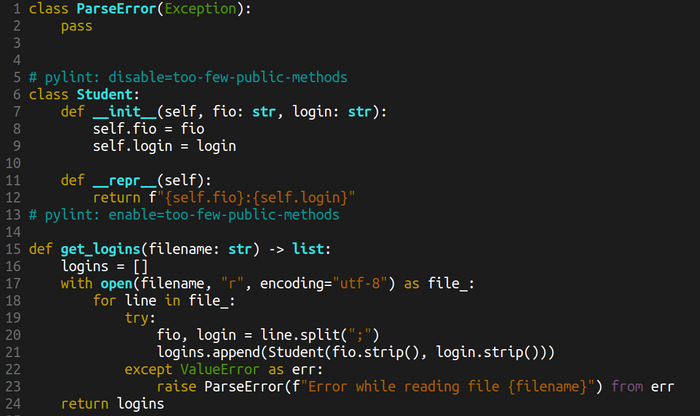
Бонусов много:
1. Мы скрываем внутреннее устройство Student. Наружу мы отдаём только пару полей, откуда мы их берём никто снаружи не знает. Вместо logins["fio"] теперь используется logins.fio.
2. Можем к Student добавлять методы. Например, вывод фамилии с инициалами в стиле Иванов И.И. — теперь это в нашей власти. В примере в repr выводится ФИО:логин. Мы полностью можем кастомизировать вывод.
3. Можем добавить новые способы создания этого студента, например, данные брать из базы данных.
Пока методов нет, можно выключать диагностику pylint, а то нам будет ругаться "у класса слишком мало публичных методов". Не забываем включить её обратно после класса.
Теперь вывод выглядит так
[Иванов Иван:anetto, Сидоров Петр:bnetto, Петров Артём:сnetto]
В телеграм-канале разбираем разные нюансы из жизни разработчика на Python и не только — python, bash, linux, тесты, командную разработку. На ютуб-канале вы можете посмотреть часовой стрим по созданию небольшого проекта на gitlab.
PS: а как лучше вставлять фрагменты кода? В цитатах нет подсветки :(