


Искусственный интеллект
6 постов

6 постов
3 поста
Это вторая часть нашего лонгрида про то, что на самом деле скрывается внутри нейросетки для генерации видео под названием SORA. Если вы не читали первую часть, то начать лучше именно с нее.
Но вы поди уже устали смотреть на какие-то пиксельные машинки и гоночки, давайте возьмём что-то крутое. Как гласит культовая фраза, Дум — круто! Поэтому слегка сменим обстановку, и переместимся в новое игровое окружение с новыми правилами.

Дум — крута!
Дум — это 3Д-экшон, суть такова... здесь взята урезанная игра с понятной задачей: продержаться в комнате с монстрами-импами как можно дольше. Можно перемещаться влево-вправо, чтобы уклоняться от огненных шаров, запускаемых монстрами в другом конце комнаты. Чем больше времени продержишься — тем лучше.
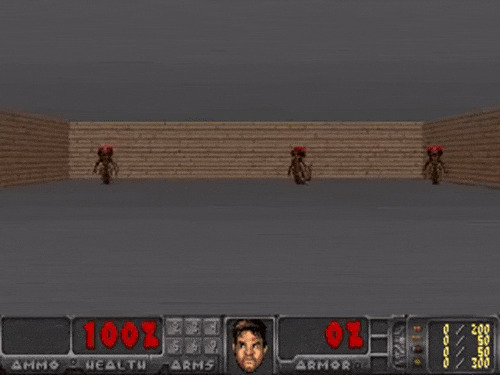
Наконец-то запустили дум не только на мобилках и холодильниках, но и на Висишечке
Первым делом необходимо переобучить энкодер-декодер, а затем — модель мира. Мы уже детально обсудили, как это делать. Единственным изменением является то, что помимо следующего состояния мы также предсказываем нолик или единичку — в зависимости от того, закончилась ли игра (если вдруг в игрока попал огненный шар). Если мы хотим тренировать бота полностью в симуляции, то как иначе нам понять, что game is over?
Затем произведём обучение нейросети, отвечающей за контроль игрока — полностью внутри симуляции. То есть, этот агент не будет играть в игру вообще: ни один латент, на основе которого принимается решение (двигаться влево или вправо), не будет получен из реальных изображений. Да и самих изображений вообще нет — только цепочка последовательно предсказываемых сигналов, которые бот мог бы увидеть от реальной игры (если бы не летал в фантазиях).
На нашу радость, с помощью декодера мы можем подсмотреть, что происходит в этой симуляции — и даже при желании поиграть в неё самостоятельно (ведь симулятор предсказывает следующее состояние не только по текущему латенту, но и по действию — движется игрок или стоит). Ниже вы можете увидеть запись симуляции. Если в нижнем левом углу робот — то играет обученный бот, а если обезьянка — то ваш покорный слуга. :) Обратите внимание на счётчик времени слева сверху (он наложен отдельным скриптом) — игра обнуляется, если игрок ловит фаербол лицом.
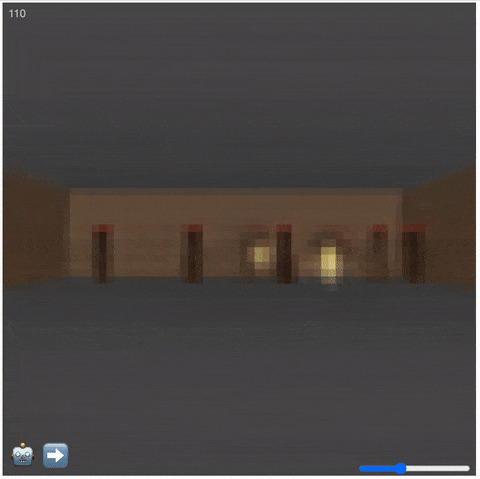
Сорри за мыльную картинку: именно так выглядит игра «в фантазиях» нашей нейросетки, а не на реальном движке
Качество записи тут ниже потому, что и энкодер, и декодер учились на картинках меньшего разрешения. Прослеживается аккуратность симуляции — есть кирпичные стены по бокам, через которые нельзя пройти, огненные шары летят по своей траектории, задаваемой в момент атаки. Однако и артефакты сложно не заметить: монстров то больше, то меньше, хотя по правилам их число должно строго увеличиваться.
Окей, ну вроде и обезьяна, и робот играют на равных (я старался, честно). Поигравшись с настройками, авторы исследования замерили качество: в 100 подряд идущих симулированных играх бот проживал в среднем 918 кадров (чуть больше 20 секунд). Теперь переходим к развязке — этого обученного бота, без любой промежуточной адаптации, заставляют играть в настоящую игру, а не симулятор. Теперь состояние среды формируется уже по известному сценарию: изображение из игрового движка обрабатывается энкодером в сигнал, с опорой на который (и на свою модель мира) бот делает предсказание, двигаться ли ему влево, вправо или замереть.
Сколько этот бычара смог продержаться не в своих мечтах, а на деле? Смог вывезти за базар? Ну, да — в реальной игре он продержался в среднем 1092 кадра (даже больше, чем в симуляции). Это большой скачок по отношению к другим методам обучения — на тот момент лучшим считался результат 820 кадров.
То есть, обучение в симуляции не то что просто кое-как перенеслось на настоящую «жизнь» (игру, которую мы симулировали), а сделало это с сохранением качества, да вдобавок еще и показало себя лучше других методов. Где-то тут полезно бы вспомнить, что новую модель SORA для генерации видео в OpenAI называют симулятором миров... но до этого мы ещё дойдем. А то вдруг окажется, что на примитивных игрушках это всё работает, а реальная-то жизнь она ж совсем не такая?
А пока вернёмся к примеру с машинкой. Может быть он вас не впечатлил? Тоже игрушка ведь. Ну едет и едет по симулированному треку, чего бубнить. Но что, если я скажу вам, что стартап Wayne, занимающийся разработкой автопилотов, ещё в далёком 2018 году опробовал метод на реальном транспортном средстве? И вот что у них получилось:
Кстати, вы обратили внимание на дождь? Не беда, если нет (ваш энкодер решил опустить эту деталь, не так ли?). Но вот что интересно: в этом случае модель училась водить в симуляторе, данные для которого были собраны исключительно в солнечную погоду. Но это не помешало обучить бота, который будет ездить в дождь! Сосредоточившись на том, что имеет отношение к принятию решений при вождении, система не отвлекается на отражения от луж или капли воды на стекле. Фактически, модель фокусируется на том, что имеет отношение к вождению, и это позволит применить подход к ситуациям, не встреченным во время тренировки.
Мы уже упомянули выше, что симуляции неидеальны: в Doom неправильно (непоследовательно) отображается количество врагов во времени. Но есть и куда более серьёзная проблема. Поскольку используемая модель мира является лишь приближением среды, то иногда она выдаёт состояния, которые не соответствуют правилам, задаваемым окружением. По этой причине бот, обучающийся в фантазиях, может наткнуться на неточность и начать её эксплуатировать. В примере с Doom это может выглядеть так:

То чувство, когда запустил в игре настолько «изи мод», что враги даже забыли тебя атаковать
Здесь бот нащупывает такое состояние, в котором симуляция не считает нужным запускать огненные шары в игрока — а значит, и умереть нельзя. И это может оказаться как просто мелким недостатком при переносе в реальную игру (или, тем более, мир), так и критической уязвимостью, приводящей к непредсказуемому непонятному поведению. Если мы будем учить автопилоты для реальных дорог в симулированной среде — лучше удостовериться, что пешеходы там не умеют телепортироваться на пару метров в сторону, когда возникает риск сбивания их машиной.
Причин неидеальности симуляции можно выделить две: недостаток данных для конкретной ситуации (из-за чего возникает «дырка» в логике симулятора) и недостаточная «ёмкость» обучаемой модели мира.
Про решение первой проблемы поговорим совсем вкратце (оно достаточно техническое, и не вписывается в рамки статьи). Один подход заключается в уменьшении предсказуемости среды в симуляторе, когда из одного и того же состояния игра может перейти в совершенно разные фазы на следующем шаге. Причём, можно управлять степенью случайности, находя баланс между реализмом и эксплуатируемостью (абсолютно случайную среду не получится обмануть — ведь она не зависит от твоих действий). Другое решение — привить обучаемому боту любопытство. Сделать это можно, например, если штрафовать его за то, что он слишком слабо меняет состояние среды (засиживается на месте), или же наоборот поощрять за новые свершения. Вы не поверите, но один из ботов в таком эксперименте начал залипать в аналог «телевизора», щёлкая каналы. В конце концов, мы не так уж сильно и отличаемся друг от друга. :)

Агент слева оказался настолько любознателен, что подсел на иглу телевидения. У бота справа телевизора в лабиринте попросту не было, поэтому он успешно выбрался. Вывод: если хотите спрятать сокровища — оставьте в лабиринте телевизор.
А что делать с ёмкостью модели? На данный момент известен лишь один гарантированный способ, который даст результат при любых обстоятельствах: масштабирование. Это означает, что мы можем увеличить размер нейросети, пропорционально увеличить размер корпуса тренировочных данных, и как следствие потратить больше ресурсов на обучение.
Все остальные способы, хоть иногда и могут сработать (взять более чистые данные/выбрать другую архитектуру модели/и т.д.), но имеют свои ограничения, а главное — могут перестать работать. Для больших нейронных сетей (в том числе и языковых моделей вроде ChatGPT) уже пару лет как вывели эмпирический закон, который показывает, насколько вырастет качество при увеличении потребляемых при тренировке ресурсов. Это называется «закон масштабирования».
И масштабирование сейчас — одна из самых главных причин, по которой вы всё чаще и чаще в последнее время слышите про AI, и почему наблюдается рост качества. Если раньше модели обучали на одном, ну может на двух серверах в течении пары недель, то теперь компании арендуют целые датацентры на месяцы. По сути, появился способ закидать проблему шапками, покупай больше видеокарточек — и дело в шляпе шапке. Это одновременно и хорошо, и плохо — с одной стороны мы точно знаем, что можно получить нейросеть получше, а с другой — она будет стоить дороже.
Вернёмся к ранее упомянутому стартапу Wayne, продолжающему заниматься беспилотными автомобилями. Они всё ещё фокусируются на создании моделей мира как вспомогательном инструменте обучения алгоритмов (прямо как OpenAI). В прошлом году они представили свою модель GAIA-1, которая... тоже была обучена предсказывать будущие кадры в видео. На видео ниже вы можете увидеть сравнение ранней модели, обученной летом 2023 года, с более поздней, на которую потратили существенно больше ресурсов («отмасштабировали»).
Да, оба видео сгенерированы почти полностью, реальным является лишь первый кадр, общий и для левой, и для правой демонстрации. Однако здесь мы наблюдаем реконструкцию с использованием декодера, а не входное изображение — поэтому уже на первой секунде заметна разница. Во-первых, вдалеке виднеются светофоры — а значит у модели мира будет задача их симулировать. Во-вторых, детали вроде машин и деревьев стали намного чётче. В-третьих, улучшилась согласованность последовательно идущих кадров (посмотрите на «плавающие» формы машин справа в самом начале). Подход один и тот же, архитектура модели и принцип обучения те же — а результат качественно лучше.
Такой продвинутый симулятор может показывать и более сложные сцены, а не просто езду по прямой. Следующий пример демонстрирует, что модель мира может помочь симулировать взаимодействие с другими участниками дорожного движения. В варианте слева белый автомобиль дает задний ход, уступая нам дорогу. Во втором развитии схожего сценария (и оба — в визуализированной «фантазии» модели!) мы уступаем дорогу и позволяем выполнить разворот — при этом наш автомобиль замедляется. Здесь оба видео порождены одной и той же моделью, разница лишь в выборе развития событий (та самая случайность в модели мира).
Вуаля, теперь можно обучать модель автопилота в симуляции, порождаемой «фантазией» модели мира, без выезда на реальную дорогу с риском для водителей, и при этом инсценировать любые желаемые сценарии. Однако нейронке есть куда расти: на её обучение потратили ресурсов в 100 раз меньше, чем на одну из лучших доступных языковых моделей LLAMA-2-70B от META (ex-Facebook, на территории РФ признана экстремистской), и приблизительно в 2000 раз меньше, чем (по слухам) OpenAI потратили на GPT-4 — самую лучшую Large Language Model (LLM) на данный момент. Представляете, какой потенциал для улучшений? (Конечно представляете — просто посмотрите на OpenAI SORA!)

Единственная разница между сгенерированными видео — количество вычислительных мощностей, потраченных на обучение SORA. На демонстрацию справа суммарно было использовано в 32 раза больше ресурсов, чем на жутенькую The Thing слева.
Ну, раз уж мы заговорили про большие языковые модели, то давайте сделаем отступление и попробуем разобраться: а есть ли модель мира у них. С одной стороны, зрением они не обладают, лишь читают текст в интернете, а с другой — ну что-то же они должны были выучить? Сразу после этого блока мы перейдем к модели SORA, с которой всё и начиналось, и в целом вы можете пропустить эту часть без потери смысла — но мимо вас пройдёт столько всего интересного!
Примерно 95–98% ресурсов тренировки больших языковых моделей тратится на обучение задаче предсказания следующего слова в некотором тексте. Под «некоторым» здесь подразумевается почти любой текст на сотне языков, доступных во всём интернете. Там есть и Википедия (как база знаний и фактов), и учебники по физике, описывающие принципы взаимодействия объектов (включая силы гравитации), есть детективные истории, и много чего вообще. Каждый раз модель смотрит на часть предложения и угадывает следующее слово. Если она сделает это правильно, то обновит свои параметры так, чтобы закрепить уверенность в ответе; в противном случае она извлечет уроки из ошибки и в следующий раз даст предсказание получше.
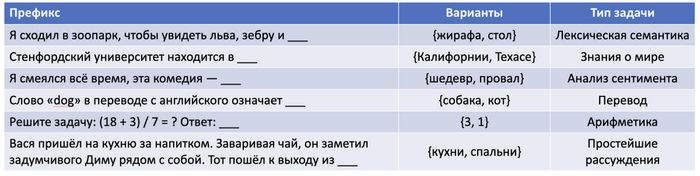
Префиксы — это примеры некоторых контекстов из интернета. Далее идут потенциальные варианты продолжения (то есть следующего слова, которое нужно предсказать). В последней колонке определен тип задачи (классификация тут условная, а не строгая и однозначная)
Давайте посмотрим на примеры в табличке выше. Чтобы предсказать следующее слово для каждого из префиксов, нужно либо обладать конкретными знаниями, либо уметь рассуждать. Иногда это может быть двумя сторонами одной и той же монеты: например, можно запомнить базовую таблицу умножения, но также через неё понять и тысячи более сложных примеров (которые в этой таблице не встречались), и затем начать корректно применять принципы математических операций.
OpenAI в этом плане двигались постепенно — первые проверки гипотезы о том, что языковая модель при обучении строит модель мира, помогающую ей успешно предсказывать следующее слово, были ещё до GPT-1. Исследователи предположили, что если взять достаточно большую по тем временам модель, и обучить её на 40 Гигабайтах отзывов с Amazon (при этом не показывая, какой рейтинг оставил пользователь — только текст), то скорее всего нейросеть сможет сама «изобрести» внутри себя концепцию сентимента. Иными словами, она сможет определять, является ли отзыв позитивным или негативным. С учётом того, что в явном виде мы никак эту информацию не сообщаем — было неочевидно, получится ли разобраться со столь сложной и абстрактной вещью, которая существует только у нас в голове: сентимент текста. Ведь это не природное явление, не закон физики — это то, как мы, люди, придумавшие свои искусственные языки, воспринимаем информацию.
Сказано — сделано. В OpenAI обучили модель, а затем рассмотрели её латент (да, там тоже модель сначала сжимает текст в понятные ей сигналы, а затем переводит его обратно в текст) под микроскопом. Так же, как мы пытались крутить 15 чиселок латента на гифке с игрушечной трассой, исследователи пытались найти такой параметр (из 4096 разных, если вам интересно), который был бы связан с сентиментом. И, как уже должно быть понятно, нашли!
Но как для текста можно понять, что вот, скажем, семнадцатая цифра в нашем латенте отвечает за сентимент? Пробуется два способа: это анализ зависимости значения от входной последовательности (текста отзыва), и сентимента генерируемого текста (= «фантазии» модели) от этого же значения. Мы как бы отвечаем на два вопроса: «Правда ли значение предсказуемо меняется из-за отзыва?» и «Правда ли, что модель опирается на это значение, то есть, сгенерированный отзыв меняется из-за значения в латенте?»
Сначала про первое. Давайте возьмём тысячи отзывов, но уже не с Amazon, а с американского аналога Кинопоиска, IMDB. Для каждого из них определим, являются ли они позитивными или негативыми. Затем будем подавать эти отзывы в модель (грубо говоря использовать энкодер для получения латента, хоть в языковых моделях это устроено чуть иначе) и смотреть, как меняется найденная цифра. Можно сделать визуализацию в виде гистограмы, на которой отзывы с разным сентиментом окрашены в разные цвета.

Горизонтальная шкала показывает, как негативные (голубым) и позитивные (оранжевым) отзывы распределились по значениям найденного нами внутри модели параметра, отвечающего за сентимент.
По графику видно, что для негативных отзывов модель зачастую показывает значения ниже нуля (аналог с визуализацией гоночной трассы — один ползунок выкручен влево), а для позитивных — выше. И «горбики» распределений почти заметно отличаются. Те отзывы, что попадают на пересечение, скорее всего имеют смешанный сентимент: может, там фильм и хвалят, и ругают? Таким образом, мы можем сказать, что состояние модели меняется в зависимости от сентимента конкретного отзыва — становится больше или меньше.
Но опирается ли нейронка на эту модель мира? Считается ли конкретно этот латент важным во время запуска симуляции (в которую мы можем подсмотреть уже не визуально, а по сгенерированному тексту)? Давайте зафиксируем все остальные значения латента (через установку одинакового начала отзыва), и сначала сгенерируем отзыв о фильме, указав большое положительное значение, а затем — отрицательное. По идее, если для модели этот признак важен, мы ожидаем увидеть очень положительный, хвалебный отзыв, а за ним — негативный.
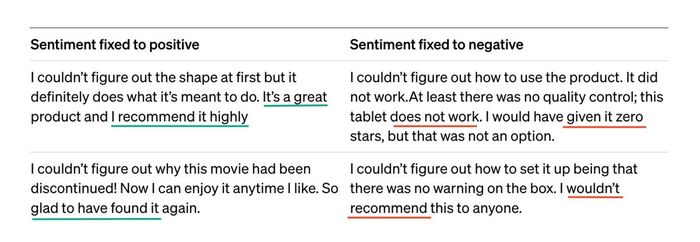
Результаты генерации. Зелёным выделены позитивные части отзывов, красным — негативные.
И ровно это учёные и обнаружили — при генерации ответ модели существенно меняет свой окрас в зависимости от лишь одной цифре в латенте. Но главная фишка в том, что мы не давали модели никакого понимания, что такое сентимент, и какими словами он выражается — вообще ничего, кроме кучи текстов. И всё же для модели мира оказалось удобнее (выгоднее?) кодировать данные так, чтобы сентимент легко разделялся, и им можно было управлять.
Этот игрушечный пример послужил толчком для OpenAI к развитию идей в модели GPT-1, а GPT-2 и 3 были дальнейшим масштабированием: больше модель, больше текстов, и как следствие более полная картина мира, выработанная внутри нейросети. Поскольку теперь кроме отзывов мы показываем тексты вообще про всё на свете, от комментариев на Дваче до учебника по физике, то модель выучивает огромное количество вещей, не только простой сентимент.
Очень сложно оценить наперёд, насколько комплексной и многогранной будет модель, и что будет зашито в её модель мира. Бывают комичные случаи: знакомьтесь, Ян Лекун, лауреат премии Тьюринга (аналог Нобелевки в компьютерных науках) за вклад в область нейронных сетей. За это его ещё называют одним из трёх крёстных отцов искусственного интеллекта. В настоящее время является вице-президентом по AI в компании META. Кажется, уж он-то точно хорошо разбирается в предмете?

Те самые трое крёстных отцов AI (Ян Лекун справа). Вообще говоря, к настоящему моменту они между собой немного все разосрались, но это уже совсем другая история...
В подкасте Лексу Фридману от 23 января 2022 года Ян говорил: «Я не думаю, что мы можем научить машину быть разумной исключительно на основе текста, потому что я думаю, что объем информации о мире, содержащейся в тексте, ничтожен по сравнению с тем, что модели нужно знать. Вы знаете, что люди пытались сделать это в течение 30 лет, верно? <...> Я думаю, что это в принципе безнадежно, но позвольте мне привести пример. Я беру предмет, кладу его на стол и толкаю стол. Для вас совершенно очевидно, что предмет будет двигаться вместе со столом, верно? Потому что он на нём лежит. Но в мире нет текста, объясняющего это! И поэтому, если вы тренируете машину, настолько мощную, насколько она может быть, например, ваш GPT-5000 или что-то еще, она никогда не узнает эту информацию. Этого просто нет ни в одном тексте».
Менее чем через год вышла ChatGPT (GPT-3.5), которая...правильно отвечала на этот вопрос. Ну ладно, ошибся дядька, наверное, где-то в учебниках физики был схожий пример. Когда в Твиттере ему за это предъявили, то он придумал новую мега-супер-сложную задачку. Сейчас-то наверное подготовился? Не стал щадящие примеры выбирать? Он выбрал задачку с шестерёнками... которую модель решила сходу, сразу же.
Тогда через месяц он придумал усложнение: «7 стержней равномерно распределены по кругу. На каждом стержне установлена шестерня, так, что она находится в сцеплении с шестернями слева и справа. Шестерёнки пронумерованы от 1 до 7 по кругу. Если бы третья шестерня была повернута по часовой стрелке, в каком направлении вращалась бы седьмая?». Родители с детьми в начальной школе уже словили флешбеки от домашки по физике, но теперь они хотя бы узнают, что... GPT-4 и на такой вопрос даёт правильный ответ.

На размышление даётся 30 секунд. Пишите в комментах, кто оказался умнее — вы или GPT-4?
GPT-4 вообще удивила многих. Вот как думаете, можно ли ответить на такой вопрос к следующей картинке, не понимая физику нашего мира, не моделируя взаимодействия объектов? Что произойдет с мячиком, если перчатка упадёт?

GPT-4 может принимать текст вместе с изображением, и умеет отвечать на вопросы, требующие визуальной информации. Тут модель правильно предсказала, что мячик подлетит наверх.
Позиция Яна не в том, что модели так не могут в принципе — он лишь не верил, что сложным физическим описаниям можно научиться либо просто по тексту, либо что такой текст вообще существует. И был не прав. Этот пример призван показать, что не стоит загадывать наперёд, что не смогут делать системы завтрашнего дня.
Конечно, модель могла не «понять» физику и уж тем более не строить модель мира, а быть обученной на таких же или уж очень похожих задачах. Однако я уже со счёта сбился от количества примеров с вопросами про очень специфичные и даже закрытые штуки, которые публикуют пользователи, но для которых, тем не менее, GPT-4 даёт адекватные ответы. Один, два, три раза — можно списать на запоминание, но были случаи...
И даже у столь мощной GPT-4 модель мира всё еще не идеальна, и то и дело приводит к глупым ошибкам. «Все модели неправильны, но некоторые из них полезны», помните?
Наконец, переходим к десерту. Такое длинное вступление было необходимо для того, чтобы наглядно продемонстрировать читателю крайне важные в контексте новой модели OpenAI тезисы:
Модели мира помогают агенту принимать решение с учётом информации о возможном будущем
Для того, чтобы успешно предсказывать будущее состояние, важно понимать лежащие в основе формирования среды процессы
Модели мира строят предсказания не в привычном нам виде, а в понятном им мире преобразованных сигналов (латентное пространство)
Мы можем заглянуть внутрь, но реконструкция не будет идеальной
Бот, обученный в симулируемой моделью мира сцене, может проявлять навыки и в реальной среде
Масштабирование модели всегда приносит улучшения, при этом многие из них неочевидны и сложнопредсказуемы
И вот теперь, когда мы разобрали концепцию моделей мира и посмотрели, для чего они могут использоваться, мы будем смотреть на примеры и пытаться понять, а в чём же именно ВАУ-эффект модели SORA. Она, как и GPT-4, выработала внутри себя какую-то модель мира, помогающую предсказывать следующий кадр в огромной разнообразной выборке всевозможных видео. Рендеринг финального изображения — это лишь реконструкция того, что предсказывает модель (потому что мы смотрим на это через призму декодера; хоть он и достаточно мощный, но имеет свои недочёты).
Пример, которым OpenAI решили похвастаться и вывести в начало своего блогпоста, вы уже видели в превью статьи. Это одноминутное FullHD @ 30 к/сек. видео, сгенерированное по текстовому запросу (промпту): «Элегантная женщина идет по улице Токио, озаренной теплым светом неоновых огней и анимированных городских вывесок. На ней черная кожаная куртка, длинное красное платье и черные ботинки, в руке черная сумочка. Она в солнцезащитных очках и с красной помадой. Шагает уверенно и непринужденно. Асфальт улицы мокрый, отзеркаливающий яркие огни. Вокруг ходит множество пешеходов.»
Во-первых, сложно не заметить точнейшее соблюдение всех деталей промпта в сгенерированном видео. Даже если сильно захотеть — разве что субъективные «элегантная женщина» и «шагает уверенно» можно подвергнуть сомнению, но, по-моему, модель справилась отлично. В этом заслуга специального приёма, использовавшегося OpenAI при разработке их предыдущей модели, DALL-E 3 (делает генерацию изображения по текстовому запросу, как MidJourney).
Так как зачастую текстовые подписи к картинкам и роликам в интернете очень короткие и несут лишь поверхностное (а иногда и неточное) описание происходящего, исследователи предложили применить умницу GPT-4 для генерации более подробных описаний. Для этого видео нарезалось на кадры, и языковая модель получала команду создать детальные подписи к происходящему в нескольких подряд идущих изображениях. Текстовые комментарии выходят не в пример длиннее, с большим количеством нюансов, поэтому обученная text-2-image или text-2-video модель гораздо охотнее обращает внимание на запрос, пытаясь соответствовать каждой его частичке. Даже лучшие платные аналоги моделей еле-еле оперируют двумя, самый край тремя предложениями — а тут мы нагрузили деталей на 5 строчек! Для DALL-E 3 процент синтетических текстов был 95%, вероятно, в SORA плюс-минус такой же.
Во-вторых, общий визуал существенно превосходит ожидания от моделей на данный момент. В Твиттере даже шутят, что «это был невероятный год прогресса AI... за один час». Тут сложно не согласиться, особенно если последнее демо, что вы видели — это Уилл Смит со спагетти из начала статьи. Но в сцене, кажется, учтено почти всё. Если заведомо не знать, что это генерация и не ждать подвоха — сразу и не скажешь. Освещение, отражения, толпа людей, переход на ближний план с детализацией текстуры кожи, плавность перемещения камеры с соответствующим изменением углов обзора на объекты в фоне. А те объекты, что пропадают из поля зрения на несколько секунд (люди сзади, синий дорожный знак на стене справа), возвращаются без изменений — такой консистентности во времени раньше и не мечтали добиться!

Моя модель мира предсказывает, что этот карандаш пропадёт из поля зрения через пару секунд. И... он испарился!
В-третьих, давайте поговорим про недостатки. Я пересмотрел видео около десятка раз, и самые заметные изменения происходят, если сравнивать начало и конец. На секундах с 55 по 59 вы можете заметить, что: 1) из рук пропадает чёрная сумочка; 2) левый лацкан куртки стал аномально большим (и даже испортил симметрию), да и правый прибавил в размере; 3) на красном платье на груди появляются чёрные пятна; 4) меняется причёска, появляется завихрение волос. Есть и комичные проблемы — обратите внимание, как левая нога превращается в правую (и наоборот) на секундах 15 и 29. И как после такого заснуть? А на секундах 16–17 ноги группы людей слева (парень, проходящий мимо двух азиаток в масках) будто бы окутаны водным шаром и очень расплывчаты.
Важно отметить, что часть этих проблем наверняка лежит на неидеальности реконструкции декодера, а часть — на проблемах с моделью мира. А может быть, собака зарыта где-то ещё, мы не знаем. Дело осложняется тем, что ни у кого, кроме OpenAI и их доверенных лиц, нет доступа к нейросети, чтобы это можно было проверить. Помните, как в эксперименте с числом в латенте, влияющим на генерацию отзыва? Тогда исследователи могли однозначно проверить, что будет, если его дёргать туда-сюда, здесь же подобного анализа не производилось. И всё же сделаю смелое предположение и скажу, что пронумерованные проблемы из абзаца выше скорее всего являются недостатками модели мира (исчез объект? поменялась форма чуть ли не самого крупного объекта в кадре? как так?!), а вот проблемы с отображением ног — уже реконструкции (потому что энкодер и декодер не посчитали нужными кодировать информацию о двух ногах, находящихся рядом).
Подобный артефакт можно было наблюдать на одном из видео выше, в симуляторе для автопилота. Там сами машины и окружение были достаточно чёткими, а вот диски колес как будто бы не крутились, и были очень шумными. Вероятнее всего, при обучении модель сочла, что куда выгоднее кодировать такие признаки, как размер авто, направление его движения, скорость, а вот насколько повёрнуты колёса в каждый момент времени уже можно подзабить — ведь это не так важно, и мы, люди, тоже не обращаем внимания при вождении на этот шум. Помните, что модель мира предсказывает будущее состояние, но не вся информация одинаково полезна для этой цели.

А так как информация не присутствует в модели мира и латенте, то и декодер не может грамотно восстановить картинку.
Но с этим связана и неожиданная хорошая новость! Раз модель мира не уделяет внимание такой детали, то и несоответствие картинки из декодированного видео настоящему миру не так критично. Ведь энкодер при сжатии видеопотока в латент для обработки (или симуляции) также опустит эти детали! В итоге, латент для реальной картинки и для «симулированной» будет почти одинаковым (хоть проблемы в реконструкции заметны невооружённым глазом). А значит наш бот, играющий в симуляторе, не заметит подвоха, и сможет потенциально оперировать в реальном мире. То, что может быть критично для создателей видеоконтента в силу неидеальности визуала, абсолютно не мешает основной цели модели SORA!
Так, и мы опять не влезли в ограничение Пикабу по количеству символов на один материал. :) Заключительная часть статьи находится вот здесь (осталось совсем немного потерпите!).
Ну что, уже успели прочитать восхищения небывалым качеством видео от нейросетки SORA у всех блогеров и новостных изданий? А теперь мы вам расскажем то, о чем не написал никто: чего на самом деле пытается добиться OpenAI с помощью этой модели, как связана генерация видео с самоездящими машинами и AGI, а также при чем здесь культовая «Матрица».

Ложки нет, Нео! Точнее, есть – но, возможно, только на сгенерированном нейросетью видео...
Это гостевая статья от Игоря Котенкова — эксперта по нейронным сетям и моего постоянного соавтора по этой теме. Я же в данном случае только немного помог ему с редактурой (и без того, надо признать, прекрасно написанного текста). Короче, заварите себе чайку и приятного вам чтения!
В середине февраля в мире AI произошло много событий (1, 2, 3), но все они были затмлены демонстрацией новой модели OpenAI. На сей раз калифорнийская компания удивила всех качественным прорывом в области генерации видео по текстовому запросу (text-2-video). Пока другие исследователи старались довести количество пальцев на руках сгенерированных людей до пяти (а члены гильдии актёров противостояли им), в OpenAI решили замахнуться на короткие (до минуты), но высококачественные и детализированные ролики — и, чёрт возьми, у них получилось!

Кадры из сгенерированного семпла. Вы же читаете текст статьи, а не смотрите на девицу в красном, верно? (Кстати, всем рекомендуем перейти позалипать и на остальные материалы, предоставленные OpenAI: тык сюда и сюда.)
OpenAI — одни из немногих, кто умеет презентовать технологию так, что обычным пользователям, далёким от AI (Artificial Intelligence, или ИИ — искусственный интеллект), сразу становится ясно: дело серьёзное. Во многие релизы Google DeepMind или Facebook AI Research сложно вникнуть, а тут смотришь — и рот невольно открывается. Просто поглядите на проработанность деталей, на физику мира, на чёткость картинки! Каждый кадр в этом видеоряде — сгенерирован от и до, и нет никакой постобработки!
Те из вас, кто запрыгнул в поезд хайпа после релиза ChatGPT и начал следить за областью AI, наверняка помнят смешные генерации с Уиллом Смитом, поглощающим спагетти. По крайней мере, именно этой нарезкой все блогеры демонстрируют прогресс моделей генерации видео за 11 месяцев.

Даже сам Уилл в итоге записал смешную пародию на эту видео, которую некоторые всерьез приняли за «наглядный пример того, как улучшилось качество нейросеток»
Достигнутая за столь короткий срок разница, конечно, поражает, но не обманывайтесь: это не совсем честное сравнение. И уж тем более не нужно экстраполировать темп изменений в будущее. Используемая модель была опубликована исследователями AliBaba 19 марта 2023 года, а само видео появилось на Reddit 28 марта — и аккурат между этими датами компания Runaway хвасталась новой моделью Gen 2: оригинальное видео с демонстрацией доступно вот тут, а ниже представлена пачка полностью сгенерированных сцен.
Не нолановская картинка, но уже заметен потенциал!
И вот уже от этой точки имеет смысл отталкиваться при оценке прогресса — так нам удастся избежать ловушки низкого старта. Получается, и результат был чуть раньше, и качество значительно лучше — удивительно, кто-то в сети снова оказался неправ...
Итак, первая когнитивная ошибка устранена, но впереди ещё пяток. Приготовьтесь услышать неочевидную правду. На самом деле, модель OpenAI была разработана не для замены актёров, специалистов по графике и даже не для мошенников из службы безопасности Сбербанка, горящих желанием набрать вас по видеосвязи от лица Германа Грефа. И, нет, оживление мемов тоже не входит в список приоритетных задач. SORA — это попытка компании обучить нейросеть пониманию физического мира, умению моделировать его, а также симулировать объекты и действия людей. И всё это — в динамике, отличающей модели работы с фотографиями от видео.
Цель такого симулятора — помочь решить проблемы, требующие взаимодействия с реальным миром. Не верите? Звучит слишком фантастично? Но даже официальный блогпост OpenAI называется «модели генерации видео как симуляторы мира» («Video generation models as world simulators»)! Сам же пост заканчивается следующей фразой:
Ведущий разработчик проекта SORA 2 на рабочем месте
Звучит как-то... антиутопично, не находите? В «Матрице» вот тоже симулировали мир людей, объектов в нём, различных взаимодействий. Но зачем это OpenAI — неужели не хватает энергии для подпитки серверов, и нужно разработать биологическую человекоподобную батарейку? Нет, основная причина — это уверенность в том, что понимание и симуляция мира являются важными вехами на пути создания Artificial General Intelligence (AGI, сильный искусственный интеллект), что, в свою очередь, является главной целью компании. Причём, эта цель остаётся неизменной с 2015 года — тогда некоторые учёные даже смеялись над самой постановкой, ибо об AGI было не принято говорить. Сейчас, когда в США вводят запрет на регистрацию патентов на изобретения, разработанных «не реальными людьми», уже не так смешно.
И всё-таки, где тут связь? Как видео-фотошоп на максималках может помочь? Существуют ли подтверждения — естественные биологические или искусственные — что симуляции работают и помогают? Насколько они связаны с реальным миром? Можно ли научиться чему-то, летая в мечтах? И зачем OpenAI обращается к ближневосточным суверенным фондам? На эти и многие другие вопросы я постараюсь ответить в нашем увлекательном путешествии! Но начнём издалека, с самых-самых основ. Сначала эти куски пазла могут не склеиваться у вас в голове в одно целое, но уверяю — в конце всё точно встанет на свои места!
Мозг развитого примата — вещь достаточно сложно устроенная. Нужно и делать огромное количество работы, и при этом тратить мало энергии. И чтобы справиться с огромным количеством информации, ежедневно проходящим через нас, мозг анализирует данные и находит закономерности. В результате люди вырабатывают ментальную модель мира (которая как бы объясняет его — как этот мир устроен, и как должен реагировать на взаимодействие с ним). Решения и действия, которые мы принимаем, в той или иной степени основаны на этой внутренней модели.
Но что куда более важно — существуют доказательства, что наше восприятие в значимой степени определяется будущим, предсказанным нашей внутренней моделью мира. Мозг — это предиктор. Интересующиеся могут почитать вот эту или эту статьи, а мы рассмотрим простой пример: бейсбол. У отбивающего есть 350-400 миллисекунд с момента подачи, чтобы отбить мяч — чуть больше, чем время моргания! И причина, по которой человек вообще может среагировать на мяч, брошенный с расстояния 18 метров со скоростью 160 км/ч, связана с нашей способностью инстинктивно предсказывать, куда и когда он прилетит. У профессиональных игроков все это происходит подсознательно. Их мышцы срабатывают рефлекторно, позволяя бите оказаться в нужном месте и в нужное время, в соответствии с предсказанием их модели мира — потому что времени на осознанное планирование попросту нет.

Кстати, подобные оптические иллюзии работают как раз потому, что ваш мозг предсказывает движение, которого... не происходит
Итак, модель мира — это выработанное внутреннее представление процессов окружающей среды, используемое агентом для моделирования последствий действий и будущих событий. Агентом в данном случае называется некоторая сущность, способная воспринимать мир вокруг и воздействовать на него для достижения определенных целей — человек или кот подпадают под это определение. Для домашнего животного «утро + громкое протяжное мяуканье = хозяин покормит» — вполне себе одно из выученных правил среды, в которой оно существует. Модель обобщается на новые и ранее неизвестные наблюдения, по крайней мере у живых организмов.
В 1976 году британский статистик Джордж Бокс написал знаменитую фразу: «Все модели неправильны, но некоторые из них полезны». Он имел в виду, что мы должны сосредотачиваться на пользе моделей в прикладных сценариях, а не бесконечно спорить о том, является ли модель точной («правильной»). Этот девиз находит своё отражение в жизни: наш мозг часто «лагает» и неправильно угадывает, казалось бы, очевидные вещи. И даже в точных науках — физики до сих пор не могут описать Теорию всего, и довольствуются аж четырьмя отдельными типами взаимодействия элементарных частиц! И ничего, живём как-то. И именно с цитатой доктора Бокса вам предлагается пройти путь до конца статьи :) Она задаст правильный настрой для восприятия информации.
К сожалению, наука продвинулась недостаточно, чтобы мы могли подключаться напрямую к ментальной модели мира внутри человеческой черепушки и рассматривать её предсказания, поэтому сделаем проще. Подключимся к мозгу, в котором эта модель мира должна проживать, и «послушаем» его сигналы (пока ещё бесплатные и без приватных каналов). Не переживайте, никому провода в голову вставлять не будут (хотя, старина Маск этим уже промышляет) — мы прибегнем к помощи функционального МРТ (фМРТ, в английской литературе fMRI). Переодевайтесь, залазьте в машину, а мы будем показывать вам разные фотографии и считывать сигналы мозга, как он реагирует на увиденное.
Схематичное изображение эксперимента
Сильно упрощая, сигнал, фиксируемый аппаратом, будет сохранён как набор чисел, из которого мы будем пытаться реконструировать изображение — прям настоящее чтение мыслей, но без магии. Сейчас самым передовым способом является — приготовьтесь — подача этих чиселок во вторую половину модели Stable Diffusion. Да, ту самую, которой все в интернете генерирут изображения сказочных вайфу и дипфейки. Всё дело в том, что эта модель уже обучена реконструировать изображения из так называемого «латентного представления» (это промежуточное состояние, с которым работает модель). Давайте для простоты посмотрим на примере:

Что происходит слева направо: наши глаза преобразуют воспринимаемую картинку в сигнал, проходящий по зрительному нерву прямо в мозг. Оттуда аппаратом фМРТ считываются активации нейронов, представленные в виде циферок (называемых латентом, или скрытым состоянием), которые передаются в обученную нейронку на реконструкцию (часто называемую декодированием). Осуществляющий эту процедуру декодер нужно дополнительно обучить, чтобы он умел воспринимать сигналы из мозга правильно, и понимал, что вот эти цифры означают мишку, а вот эти — самолёт.
С одной стороны, мозгу этих чиселок хватает для того, чтобы принимать решения и ориентироваться в пространстве (если игнорировать неидеальность аппаратуры для считывания сигнала). А с другой, декодер от нейронной сети, обученный генерировать картинки, умеет воспроизводить изображение так, чтоб оно почти не отличалось от реальных картинок (нуууу, с натяжкой, ок? подыграйте мне). Те огрехи, которые мы видим на примере — это в большей степени результат неидеальности считывания сигнала, а не проблема реконструирующей нейронной сети, ведь сама по себе она умеет выдавать офигенно правдоподобные рисунки.

Сверху оригинал, который видел человек, снизу реальная реконструкция по сигналу мозга, считанному фМРТ. Вот сайт проекта, и там же — статья с более детальным объяснением.
Мозг не видит изображения, он оперирует в пространстве сигналов, получаемых и преобразуемых сенсорной системой, и в нём же строит удобную ему модель мира. Это менее очевидно для зрения, так как вы прямо сейчас смотрите на этот текст и видите его в реальном мире. Но на самом деле это реконструкция сигнала в вашей голове — иногда она барахлит, и могут возникать галлюцинации, неотличимые от реальных, потому что мозг уверен, что он что-то видит.
То, что в нейронных сетях давно используются декодеры (и в том числе для реконструкции из сигналов сенсорной системы), мы уже поняли. Но что тогда является аналогом сенсорной системы, переводящей наблюдения в латентное пространство? Это кодировщик, или энкодер: он как бы «сжимает» исходные данные в специальное представление, хранящее ключевую информацию, и при этом опускающее ненужные детали и шум.
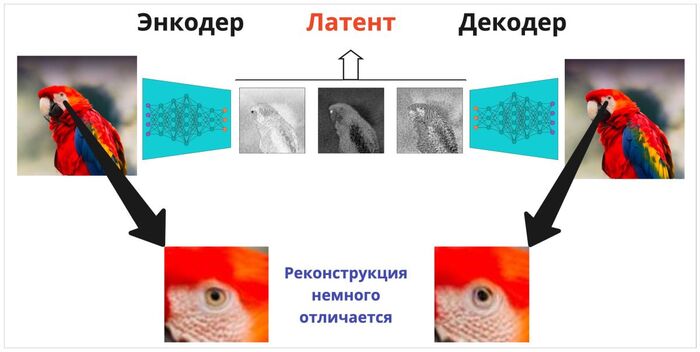
Латент может хранить некоторые очертания исходных наблюдений, но несёт совершенно другую информацию. Вместо указания на цвета пикселей там записан как бы «смысл» региона фотографии. Так что результат реконструкции не будет совпадать с оригиналом идеально!
Только наш мозг умеет делать это практически с самого рождения (спасибо эволюции), а нейронные сети нужно тренировать. Такие модели будут называться автокодировщиками, и для обучения используется следующий трюк: модель каждый раз пытается сделать так, чтобы последовательное применение энкодера и декодера (см. визуализацию выше) к изображению приводило к результату, близкому к оригиналу — при этом в серединке остаётся вектор чиселок (латент), который хранит в себе информацию. И его размер куда меньше, чем входное изображение, что заставляет модель компактно сжимать данные — однако благодаря умному декодеру выходная картинка почти неотличима от оригинала.
Давайте для демонстрации игрушечной модели мира запустим компьютерную игру: гонки с видом сверху.

Вспоминаем девяностые и несёмся им навстречу на полной скорости!
Соберём несколько минут записи игры, обучим автокодировщик. На этом этапе мы не оперируем никакой информацией, кроме одного кадра за раз — это очень важно. Картинка на входе, картинка на выходе, а в серединке какой-то набор сжатых данных (латент), состоящий всего из 15 значений. После обучения можно визуализировать результат: взять изображение из реальной игры (которое модель могла никогда не видеть), сжать его энкодером (=применить сенсорную систему) в 15 чисел (=сигналы в мозге), а затем обработать их декодером (=реконструировать).

Реальное изображение (слева) подаётся в обученный энкодер, после чего полученный латент реконструируется декодером в картинку справа. Процесс повторяется для каждого отдельного кадра.
Видно, что ключевые аспекты выражены хорошо: машинка всегда на месте, геометрия трассы и ширина дороги почти идеально сохранены, и в то же время малозначительные детали вроде ромбиков на газоне утрачены (потому что они, как оказалось, менее приоритетны при реконструкции).
Занятно, что мы можем манипулировать числами в латенте и смотреть, как они влияют на «восприятие» — для этого их нужно декодировать, как бы отвечая на вопрос: «Что было бы видно, если мы считаем вот такой сигнал?».

Слева — оригинал из игры, по центру — латент, значения в котором мы вручную изменяем. Справа представлена реконструкция с применением декодера. Видно, как одна из нижних настроек полностью ломает мир игры и геометрию трассы.
Это уже интересно! На людях схожий опыт не проводили, однако контролировать тараканов электрическими стимулами можно даже сейчас. Только если гринписовцы спросят — я вам не говорил.
Теперь сделаем чисто технический шаг. У нас есть «сигнал от сенсорной системы» (но в терминах компьютеров), и мы можем попытаться обучить бота играть в игру. Цель в гонке — проехать как можно больше клеточек по дороге, не съезжая на газон. Время ограничено, как и максимальная награда, поэтому чем лучше бот будет держаться на трассе — тем выше мы его оценим.
Не будем вдаваться в подробности обучения такой нейросети, а просто рассмотрим саму систему. Сначала изображение из «мира» игры попадает в энкодер, после чего он кодирует картинку в 15 чисел. Затем на основе этих чисел мы строим простое уравнение, которое указывает, стоит ли машинке ускоряться, тормозить, или поворачивать влево-вправо (то есть, по 15 числам на входе нам нужно более-менее оптимально предсказать 4 числа, которые отвечают за «дергание руля» и педали газа/тормоза).
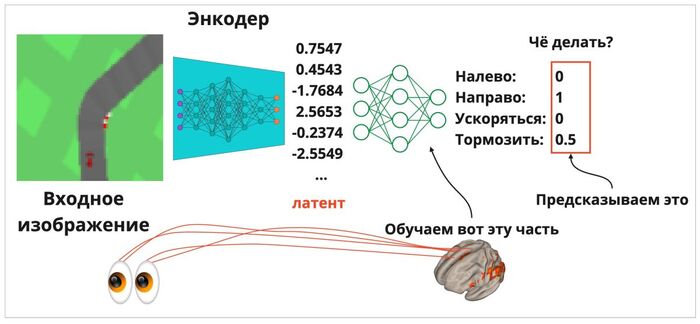
Подаваемое в энкодер изображение трассы преобразуется в короткий числовой сигнал (латент). Нейронка («мозг») учится понимать, как нужно управлять машинкой в зависимости от подаваемого сигнала — так, чтобы по итогу рулить не хуже Михаэля Шумахера.
Под капотом выучивается стратегия в духе «если первое число такое-то, а второе сильно больше нуля, и..., то нужно скорее поворачивать направо». Нейрока поняла, что на такой сигнал нужно реагировать вот так, а на иной — совсем иначе. Как итог, бот вроде и будет ориентироваться на гоночной трассе, и средне управлять машинкой. Легко заметить, что он раскачивается туда-сюда и часто не вписывается в крутые повороты.

Так, на этом этапе у нас пока всё-таки вместо Михаэля Шумахера получился бухой сосед Михал Палыч без водительских прав...
Само по себе сжатие данных с целью дальнейшей реконструкции не всегда приводит к появлению качественной модели мира. Как мы обсуждали выше, важно, чтобы эта модель помогала принимать решение о будущих событиях и потенциальных развязках — именно тогда она становится полезной. Полученная же модель имеет фиксированное представление об определенном моменте во времени (она ведь рассматривает каждый кадр строго по отдельности), и не имеет большой предсказательной силы.
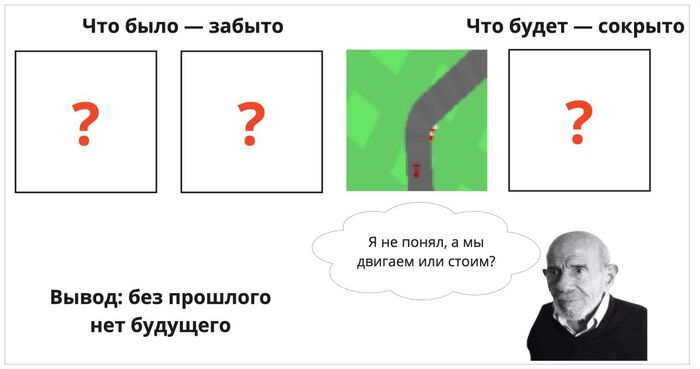
Без понимания истории трудно сказать с уверенностью, что нам делать дальше — то ли это начало гонки и надо разгоняться; то ли мы, наоборот, на полной скорости летим в кусты и надо тормозить?
Сейчас же по статичной картинке ни мы, ни бот не можем понять — быстро ли едет машина? Поворачивали ли мы влево или вправо? И уж тем более нет никакой интуиции, подсказывающей, что уже пора пристёгивать ремень — потому что мы летим в отбойник.
Давайте это исправим. Добавим отдельную модель, которая учится предсказывать, что ждёт в будущем. Причём, предсказывается не следующий кадр (откуда? мозг его не видит), а следующий латентный вектор (который соответствует тому, как бы мозг закодировал в свой внутренний сигнал восприятие этого следующего кадра реальности). По сути, модель отвечает на вопрос «с учётом текущего состояния и действий, которое я предпринимаю — каким будет следующее полученное состояние окружения?».
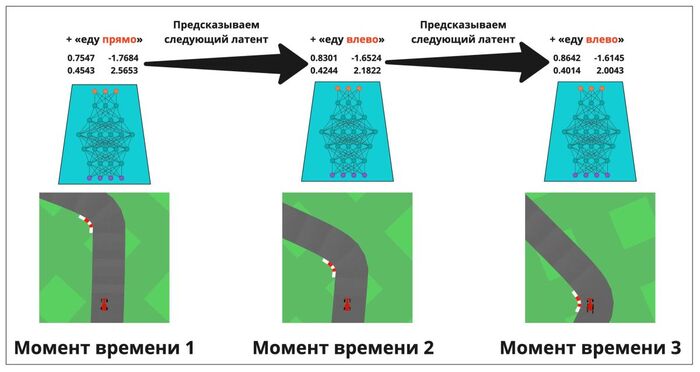
Берём картинку, получаем латент, добавляем действие — и пытаемся угадать, что будет дальше (новый латент). Затем перемещаемся немного в будущее, смотрим, что получилось, совпала ли новая реальность с ожиданием. Если нет — корректируем нашу картину мира.
Итого в системе есть 3 отдельных части:
Автокодировщик с энкодером и декодером (2 половинки одного целого), помогающие сжимать изображение и производить деконструкцию из латента.
Модель предсказания следующего латента. Хоть это и не отображено на картинке, но сам латент немного изменился — к нему добавился вектор внутреннего состояния (к 15 числам приписали ещё несколько). Он выступает в роли накопителя опыта, или подсознательной памяти, помогая разбираться, что происходило в предыдущие пару секунд. Мы не задаём ему никаких ограничений, лишь просим быть максимально полезным в задаче предсказания ближайшего будущего — что «запомнить» модель решает сама. В данном случае логично предположить, что туда сохраняется скорость, динамика её изменения (тормозим или разгоняемся), совершался ли недавно поворот, и так далее — всё то, что поможет угадать будущее.
Обучаемый бот, который видит только латенты и делает по ним выводы.
Ииии... предложенный метод моделирования будущего позволил двум учёным, Дэвиду Ха и Юргену Шмидхуберу, обучить пачку ботов, которые являлись лучшими в разных играх — от гонок до стрелялок. Такие модели мира, как они их назвали, опираются на наблюдения за процессом работы мозга человека, и все эти предисловия и примеры были приведены не для красного словца.

О, стало сильно лучше: уже заметен существенный прогресс на пути от Михал Палыча в алкогольном делирии к высококлассному Шумахеру, согласитесь?
Но, возможно, вы задаётесь вопросом — как блин это всё связано с OpenAI SORA? Мы же начали с генерации видео! И вообще насколько полезен такой подход — может, вне гоночек он и не работает вовсе? Что ж, тут пора заметить, что SORA генерирует кадры видео последовательно, учась отвечать на вопрос: «что же будет дальше для вот такой картинки»? И — вы не поверите — делает она это тоже в латентом пространстве, только своём, в котором куда больше 15 цифр.
В предыдущей статье мы рассказывали о том, как тренируется ChatGPT — предсказывая по цепочке каждое следующее слово в длинном тексте. Упрощенно можно сказать, что похожим образом действует и SORA, предсказывая каждый следующий кадр в видео-последовательности. (На самом деле, там всё чуть сложнее: каждый кадр еще внутри нарезается на небольшие «ошметки», размерами условно 32х32 пикселя, и эти кусочки тоже генерируются один за другим — но нам на такой уровень деталей сейчас погружаться нет необходимости, оставим это для другого раза.)
Теперь вернёмся на шаг назад и подумаем вот о чём. В нашей системе появилась отдельная модель, которая предсказывает латент, соответствующий следующему наблюдению (следующему кадру игры или видео). А наш бот не опирается ни на что другое, как на этот самый латент (плюс внутреннее состояние, но оно обновляется само по себе во время игры).
Давайте сделаем сумасшедшее: отключим игровой движок, который задаёт нам правила игры, и пустим обученного бота играть в своих «фантазиях». Фантазией тут называется предсказание ментальной модели мира о будущем: что могло бы произойти, если бы вот в этой ситуации я бы сделал так. В таком случае нам не нужен энкодер — потому что латент мы получаем через предсказание модели мира, а декодер по сути нужен только для того, чтобы нам самим подсмотреть, что происходит — бот на это никак не опирается. Он играет исключительно «в своей голове» и сам с собой, на циферках (красивая картинка ему для этого ни к чему).
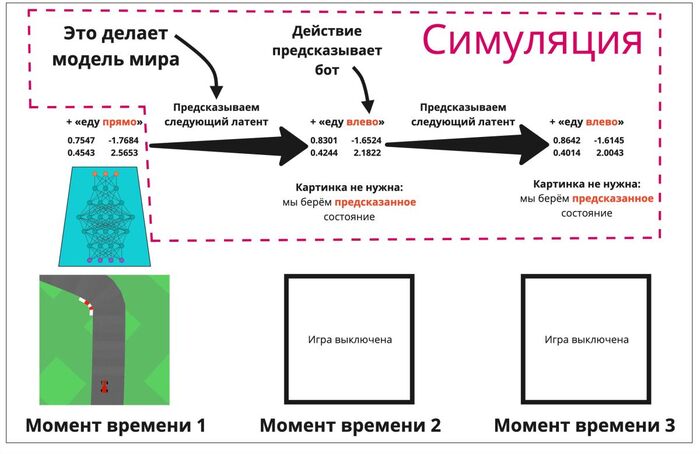
Реальный кадр только первый. По его латенту и предсказанному ботом действию моделью мира формируется второй латент. На его основе бот снова предсказывает действие, и так далее. Всё, что выделено в пурпурную рамку — это фантазии модели, симуляция.
Похоже на бред, который не сработает? Давайте проверим, а заодно подключим декодер для визуализации происходящего:

Слева снизу можно увидеть предсказания бота для управления машинкой (влево или вправо двигаться, нужно ли ускоряться).
Не напоминает ваши сны? Общие черты «реального» мира прослеживаются, а действия и вправду влияют на то, что происходит вокруг: машинка может проехать поворот. Но какие-то части среды всё же выглядят размыто. И всё это симулировано выученной моделью мира. Нейронка просто наблюдала за тем, что происходит в игре при тех или иных обстоятельствах, с учётом действий водителя машинки, и теперь сама выступает в качестве игрового движка.
Иными словами, модель мира = симулятор. Запомнили. На каждом шаге игры мы считаем, что случилось то, что предсказала эта модель, и движемся дальше. И мы с вами только что увидели, что бот, обученный в реальной игровой среде, в большей степени функционирует и в среде «фантазий». Возникает вопрос: можем ли мы обучить агента внутри симуляции так, чтобы можно было перенести его навыки обратно в реальный мир?
Здесь мы уже незаметно достигли предела по количеству впихуемого в одну публикацию на Пикабу, так что продолжение лонгрида можно прочитать вот здесь. Там мы разберем самое интересное: можно ли научить андроидов мечтать об электрочертях из Doom, как обучить условную Теслу ездить без водителя (не угробив 100500 пешеходов в процессе), а также как перейти от нейросети для генерации видео к сверхсильному искусственному интеллекту?
Все самые важные и интересные финансовые новости в России и мире за неделю: у россиян забирают загранпаспорта из-за «неправильных» шрифтов, государственная база данных с банковскими картами и паролями путешественников, новые санкции, первая частная победа в суде РФ над Euroclear, а также расовый скандал с нейросеткой гугла Gemini AI.
Полтора года (с августа 2022-го) Эльвира Набиуллина терпела и не трогала российские банки, но 21 февраля всё же не удержалась и отозвала лицензию у Киви-банка.

Как говорится – при ближайшем рассмотрении, волосатый новозеландский воробей оказался скорее мертв, чем жив
В качестве причин отмены банка, ЦБ назвал его активное участие в сомнительных операциях, а именно: облегчение расчетов между криптанами, нелегальными букмекерами, вывод ворованных денег через подставных «дропов», а также покупка игр от загнивающего запада через казахстанский Steam (окей, последний пункт – это шутка, думаю, Эльвира Сахипзадовна не в курсе о том, как конкретно ты смог купить Hogwarts Legacy).
Тут надо сказать, что сама группа компаний QIWI больше известна не столько своим банком, сколько популярными Киви-кошельками – говорят, они есть (были) аж у 14 млн человек; а также системой международных переводов Contact. Если клиентам Киви-банка всё гарантированно возместит АСВ (в пределах суммы 1,4 млн руб.), то перед держателями средств на Киви-кошельках и по зависшим Contact-переводам таких обязательств нет. Впрочем, ЦБ говорит, что денег у самого банка в ходе банкротно-ликвидационных процедур должно хватить на возмещение всем – но для этого вам нужно обязательно оставить заявку на сайте АСВ.
«Вёрстка» дозвонилась на горячую линию Агентства по страхованию вкладов и выяснила, что владельцам электронных кошельков нужно подать обращение через сайт с указанием паспортных данных и номера кошелька, к письму необходимо приложить сведения об открытии кошелька, чеки, информацию о переводах — все, что может подтвердить ваши права на кошелек.
С платежными системами, через которые россияне могли ранее переводить деньги за рубеж, в последнее время дела обстоят не очень: «Юнистрим» забанили санкциями США полгода назад, Contact добил вот сейчас уже наш Центробанк, а «Золотая корона» осторожно не позволяет делать переводы с карт санкционных банков (а такие сейчас в России – уже почти все крупные). Крутитесь как можете, короче!
В Хвиттере задаются вопросом
Как вы помните по одному из прошлых выпусков новостей, в конце января прошла сделка по выкупу Qiwi за полцены ее же собственным директором. Тогда мы обсудили, что это выглядит как некрасивое «обувание» инвесторов в акции компании, а сейчас вот после новостей об отзыве лицензии у банка, их котировки упали еще на 50% с тех пор. Выходит, выкуп-то был как бы по «справедливой» цене, без всяких скидок по факту? 🤔
Думаю, новый собственник месяц назад был уверен, что с ЦБ всё получится без проблем зарешать (как это уже удавалось сделать много раз в предыдущие несколько лет), и радовался удачной сделке. Тем более, что Минфин-то эту сделку утвердил – значит, типа, государство благосклонно к компании! А по итогу вышло – получил загибающийся актив, да еще и в бюджет РФ придется заплатить обязательный сейчас взнос в размере 10% от любой сделки по выкупу бизнеса.
Что будет дальше с бизнесом Киви – пока не очень ясно. С одной стороны, у них там и помимо самого банка всякие сервисы есть. С другой, почти все они так или иначе завязаны на платежные сервисы, а кто из банков захочет сейчас связываться с волосатым фруктом после такого недвусмысленного сигнала от ЦБ «не трогайте, оно токсичное!» – непонятно.
Если выкуп российских бизнесов у иностранцев за 50% от их рыночной стоимости вам кажется хитро-дерзким ходом, то это вы еще не видели, что придумал Совкомбанк. А именно: ребята предложили инвесторам выкуп еврооблигаций, выпущенных банком ранее, за 10% от номинала (то есть, за одну десятую, Карл!).
Учитывая, что зарубежные инвесторы никакого профита от этих облигаций получать сейчас не могут (все платежи заблокированы в этих ваших Евроклирах), многие из них давно уже мысленно посписывали эти бумаги «в ноль» – так что, поди, найдутся желающие отдать их за бесценок.

Признаюсь, в свете этой новости трактовка логотипа банка заиграла для меня новыми красками
Жалко, физлица воспользоваться таким лайфхаком не могут. А то я бы так взял ипотеку в банке, а через пару лет заявил бы: «парни, платить больше не получается, но готов вам отдать 10% от всей суммы, и будем в расчете!»
В прошлом выпуске мы с вами обсуждали «парадокс IPO»:
Популярные первичные размещения акций легко могут подскочить сразу после листинга на бирже на +40% (см. Диасофт), только вот аллокацию инвесторам, желающим поучаствовать в этом веселье, дают на уровне 1–2% от их заявок.
В других IPO, наоборот, всем желающим щедро отсыпают акций в объеме их пожеланий. Только вот после листинга бодрого скачка вверх по таким размещениям отчего-то не происходит.
На прошлой неделе мы как раз увидели пример размещения второго типа: на биржу вышла компания с красивым названием «Алкогольная группа Кристалл». Инвесторы на IPO взяли акцию по 9,5 руб., а на бирже она сразу провалилась вниз на 15% до 8,1 руб. Зато аллокацию дали от души – пишут, что под 80% от поданной заявки...

Не знаю как вы, но я при словах «алкогольная группа» представляю скорее что-то такое
А знаете, кто точно никогда не теряет деньги на участии в IPO? Брокеры, конечно же! ЦБ тут как раз пожаловался на то, что ряд брокеров креативно подходят к взиманию комиссий за участие: рассчитывают их на весь объем поданной заявки, даже если реальная аллокация составила в итоге всего несколько процентов от нее.
После 24 февраля 2022 года президент РФ успел напринимать кучу всяких так называемых «антисанкционных» указов, которые в том числе затрудняют денежные операции с рублями и валютой для россиян. Многие из этих указов принимались в суматошно-хаотичном порядке, поэтому местами случались казусы: так, в марте 2022 года российским гражданам случайно запретили продавать ценные бумаги на зарубежных брокерских счетах (в июне обратно разрешили), а в марте 2023-го неразрешенными внезапно оказались уже любые сделки купли-продажи на зарубежных биржах (разрешили обратно в ноябре).
При этом, всё это время в отношении этих указов ситуация была странной: ограничения как бы есть, а ответственность за их нарушение как бы не определена. Юристы осторожно предполагали, что кара за несоблюдение указов президента может быть аналогичной штрафам за нарушение валютного регулирования (до 40% от суммы операции) – т.к. конкретно в кодексе об административных правонарушениях (КоАП) эти указы не поименованы, а валютные статьи по смыслу ближе всего. Но это всё носило спекулятивный характер.
Ну и вот, Ведомости пишут, что законопроект об официальном вводе соответствующих штрафов в КоАП реанимировали и планируют принимать в скором времени (не могут пока только договориться, что делать с теми бизнесами, кто неправильно продает за рубли валютную выручку). Как только его протащат через Думу – так сразу и заживем счастливо с полным осознанием того, как конкретно нас будут наказывать!

Как думаете, какое наказание в итоге впишут в КоАП? Вангую, что всё-таки аналогичное штрафам за нарушение валютного законодательства: 20–40% от операции
Телеграм-канал SHOT пишет, что многие россияне столкнулись с изъятием загранпаспортов на границе из-за «неправильных шрифтов». МВД это опровергает, но как-то вяло – они не говорят «да ну, какие неправильные шрифты, что за бред??», а скорее «мы что-то не видим всплеск заявлений на замену паспорта... наверное, это значит, что у всех всё норм».

Фрагмент внутренней инструкции, который выложили SHOT, выглядит, тем временем, довольно правдоподобно. Ножка у семерки, видите ли, слишком ровная...
Источники Коммерсанта эту информацию подтверждают и говорят о том, что проблеме подвержены загранпаспорта старого образца (сроком действия на пять лет и без биометрии), которые выпускали в последние пару лет: там кто-то в паспортном столе неудачно поигрался со шрифтами – и проиграл. Кстати, на прошлой неделе еще появилась новость, что обладателям паспортов без биометрии со второй половины 2024 года возможно закроют въезд в Евросоюз.
Короче, хозяйке на заметку: Если у вас единственный загранпаспорт без биометрии – то это никуда не годится, срочно идите получать новый на 10 лет. Да даже и если у вас уже есть один десятилетний, то всё сравно сходите и получите еще один запасной – так можно делать, в том числе даже и за рубежом.
Дело в том, что с декабря 2023 года вступил в силу новый закон о конфискации российскими госорганами «недействительных» загранпаспортов с довольно размытыми критериями – поэтому, имея на руках только один документ, сильно выросли риски в какой-то момент оказаться на границе с нежелательной для вас стороны вообще без документа.

На всякий случай – проверьте внимательно свой загранник, нет ли там опечаток. Кривизну ножек у семерок еще не забудьте измерить! [Источник: 74.ru]
И еще сразу в тему: ТГ-канал Offshore Channel обратил внимание на то, что Минфин предлагает обязать зарубежные консульства уведомлять российскую налоговую о выдаче гражданам паспортов за пределами РФ. Логика здесь простая: получил паспорт не на Родине – какой-то ты странный парень, поди по-тихому эмигрировал из России, и никому не рассказал! Возможно, тут есть основания для бодрящих доначислений налогов...
Коммерсант пишет, что с 1 сентября Минтранспорта хочет обязать всех перевозчиков (авиа-, водных, железнодорожных, и других) передавать в единую базу помимо данных паспорта и билета – также данные об IP-адресах, телефонах, адресах электронной почты и паролей учетных записей (wut?). При оплате банковской картой перевозчик должен будет передать четыре последние цифры карты и наименование банка (жалко, что без пин-кода и CVV-номера).
В Минтрансе говорят, что всё это делается ради более эффективной ловли коварных преступников, а сама база данных будет сверх-защищена от любых взломов и утечек. 🤔
И к другим новостям: Роскомнадзор сообщил о том, что в 2024 году произошла утечка персональных данных россиян на 500 млн строк. Что конкретно утекло, откуда и куда – из заявления не понятно, но сам объем этой единственной утечки уже почти превысил совокупные сливы за весь 2023 год.
Но это ничего: думаю, в 2025 году можно будет легко побить этот рекорд еще раз – как только авиакомпании наладят передачу в Минтранс айпишников, телефонов и паролей туристов...

Новостью поделился Милош Вагнер (замглавы Роскомнадзора). Хотел пошутить, что это «не тот, что вы подумали, а Вагнер здорового человека» – но как-то тоже неловко выходит такое говорить
На прошлой неделе к 24 февраля западные страны подгадали новый большой пакет с пакетами санкций.
США включили в санкционный список оператора платежной системы «Мир»: на использование карт внутри России это не должно повлиять, а вот работать в «дружественных» странах они вряд ли продолжат – кажется, в минувший вторник мне в последний раз довелось расплатиться российской карточкой за хачапури в Ереване.
Кроме того в американский SDN-список добавили кучу малоизвестных банков: Авангард, Ростфинансбанк, Челиндбанк, Модульбанк, Датабанк, Быстробанк, Морской банк, МФК, Ижкомбанк, Кавказский Комсельхозбанк и СПБ Банк. Последний является депозитарием печально известной СПБ Биржи – нам как бы дополнительно намекнули, что разморозки активов российских инвесторов на этой бирже можно в ближайшее время сильно не ждать.

Также под штатовские санкции угодил застройщик «ПИК». Теряюсь в догадках – неужели они хотят помешать экспорту человейников в США? 🤔
В общем, ничего сильно существенного в американском списке мы не увидели. Накануне было много обсуждений, что велик риск попадания в SDN Мосбиржи/НКЦ, что привело бы к проблемам с биржевой торговлей долларами. На волне этих опасений даже произошло «раздвоение» курсов доллара на Мосбирже: обычно гуляющие друг за другом курсы с расчетами сегодня (USDRUB_TOD) и завтра (USDRUB_TOM) разъехались в разные стороны: «сегодняшний» доллар в какой-то момент уходил за 100 руб., в то время как «завтрашний» оставался на уровне 93 руб.
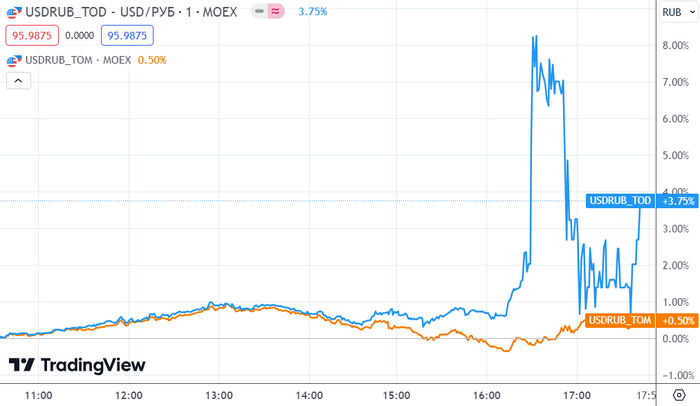
TradingView: Кто-то очень сильно хотел успеть закупиться баксами перед выходными, и готов был платить за это до 8% премии
Пробежимся также кратко по новым санкциям от других стран (ничего сильно интересного там нет):
Евросоюз: Ввел 13-й пакет на 106 физических и 88 юридических лиц. Из любопытного пожалуй только то, что в списке оказалось много не-российских компаний: из Шри-Ланки, Китая, Индии, Сербии, Казахстана, Тайланда и Турции. То есть, пытаются оказать давление именно вторичными санкциями на партнеров.
Великобритания: Расширила список на 50 позиций, включая ряд руководителей российских компаний. Отдельным списком прошли шестеро руководителей колонии ИК-3 «Полярный волк».
Канада: 153 организации и 10 физлиц, включая президента Федерации шахмат России Андрея Филатова.
Австралия: 37 организаций и 55 физлиц – включая Киркорова, Газманова, Расторгуева и Баскова.
Заголовок звучит очень круто! Но есть один нюанс: чувак хотел взыскать с Евроклира $582 тысячи, а суд ему присудил только $10к (купоны и дивиденды, но без потерь по самим подзаморозившимся бумагам).

Наш герой, Роман Прудентов. Что-то есть в нем от советского Нила Патрика Харриса
Интересы Романа отстаивала юридическая фирма Stonebridge Legal – к гадалке не ходи, стоимость услуг юристов была повыше «жалких» отсуженных $10 тыс. С другой стороны – Роман там как бы работает партнером, так что вряд ли платил по прайс-листу. Да и ПЕАР неплохой для фирмы вышел!
В мае 2023 года мы отмечали достижение капитализацией Nvidia отметки в $1 трлн, а уже на прошлой неделе акции скакнули после публикации хорошей отчетности на очередные +15%, и компания стоит уже целых 2 триллиона баксов.

Тем временем, Интел может похвастаться в лучшем случае скромной капитализацией менее $0,2 трлн
Заодно Nvidia побила рекорд по самой большой прибавке за одну торговую сессию в истории: компания стала дороже аж на $277 млрд всего за день – такое чувство, что всё следующее столетие мы только эти чипы из графических ускорителей и будем на хлеб намазывать и кушать!
Интересно, кстати, что главная американская радетельница за вложения в прорывные инновационные компании – инвесторка Кэти Вуд с фондом ARKK – всю Нвидию продала в конце 2022 года и пропустила рост котировок ее акций в пять раз. Как выяснилось – не все инновационные фонды одинаково полезны! (С начала 2021 года ARKK находится в просадке более чем на 60%, несмотря на впечатляющую динамику американских тех-компаний.)

Твое лицо, когда инвесторы в инновационный фонд ARKK спрашивают «ну и сколько мы там заработали на ралли Nvidia? как это – ноль??»
Главный англоязычный мега-форум Reddit собирается выходить на IPO (несмотря на то, что компания продолжает генерировать убыток на уровне $90 млн в год). Под это дело из поданных в SEC документов еще выяснилось, что наш пострел Сэм Альтман из OpenAI владеет почти 9% в Reddit. Ясно-понятно теперь, почему OpenAI решили GPT-2 в 2019-м тренировать именно на ссылках с Реддита!
Кстати, лицензирование данных с форума с целью обучения на них нейросеток становится сейчас существенной частью выручки Reddit (уже заключили контрактов со всякими Гуглами на $200 млн – примерно четверть годовой выручки, хоть это и не относится только к одному году). Кто бы мог подумать 18 лет назад, когда Реддит только появился, что продажа нагенерированного пользователями щитпостинга в будущем может оказаться прибыльной штукой?

Стив Хаффман (CEO Reddit) и сам неуловимо похож на того самого школьника, который пишет в сети «я твой мамка труба шатал!». А потом ChatGPT всё это с забора читает и учится...
Все американские фонды ETF по закону обязаны регулярно распределять получаемые ими купоны и дивиденды в адрес своих инвесторов. Мне это всегда казалось странным – зачем такое странное требование, почему нельзя их удобно сразу аккумулировать внутри фонда (как это делается часто в европейских ETF)?
Разгадка оказалась банальна: налоги на проценты/дивиденды в Штатах составляют до 37%, а capital gain облагается по ставкам гораздо ниже (до 20%). Дядя Сэм не хочет, чтобы ты платил меньше налогов!
А теперь к новости: пацаны из инвесторской тусовки Alpha Architect покумекали, и придумали способ, как получать стабильную доходность на уровне трехмесячных US Treasuries (примерно 5,5% годовых сейчас) – но так, чтобы при этом не получалось процентного дохода к распределению (и, соответственно, к налогообложению). Фонд назвали BOXX (коробочкка?). Объяснять принцип долго, но там конструкция из говна и палок [зачеркнуто] покупки и продажи опционов на акции с хитрой утилизацией налоговых убытков.
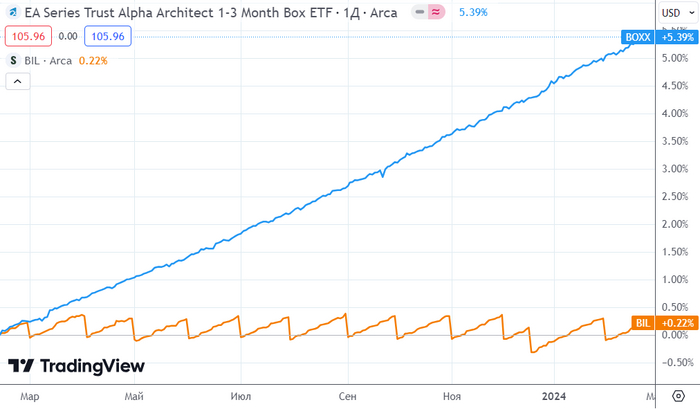
TradingView: Котировки (без учета выплаты дивидендов) BOXX и более классического фонда BIL на короткие US Treasuries: нетрудно заметить, что BIL не растет в цене, т.к. всю полученную доходность распределяет инвесторам, а BOXX всё аккумулирует в цене
Я вот думаю: стоит ли американцам рассказывать, чё может пойти не так со всеми этими «сверхнадежными конструкциями на деривативах»? А то был у нас тут один надежный ETF с хеджированием курса деривативами – да потом и обнулился внезапно в марте 2022-го...
В конце 1980-х все думали, что японцы захватят весь мир – ну, по крайней мере, в экономическом смысле. Поэтому японский фондовый рынок тогда стоил даже больше, чем американский.
Правда, длилось это веселье недолго: с 1990-го японские акции как начали падать, да так и не могли толком восстановиться многие десятилетия. Только на прошлой неделе, 34 года спустя, индекс Nikkei 225 опять достиг того же уровня оценки, что и на пике пузыря 1989 года.
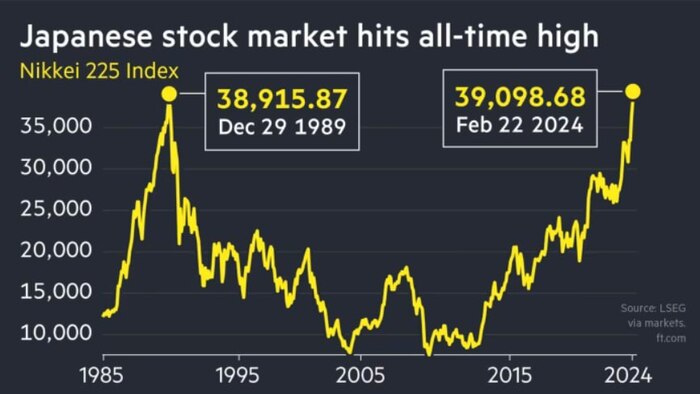
Правда, это всё без учета инфляции. Но зато и дивиденды тоже не учитываются. Короче, выводов не будет, но картинка всё равно вышла поучительная =)
На прошлой неделе американский Хвиттер начисто порвался по поводу гугловского чатбота AI Gemini.
У Google уже раньше были проблемки с расовой темой, когда в 2015 году выяснилось, что их нейросетевой распознаватель объектов на фотках уверенно подписывает слово «горилла» под чернокожими людьми. Гуглу тогда пришлось заняться окончательным решением горрильного вопроса: нет, они не натренировали нейросетку лучше различать людей и обезьян – а просто заставили ее забыть о существовании горилл, лол.
Видимо, памятуя об этом провале, они сделали особо сильный упор на том, чтобы научить свою AI Gemini при генерации картинок практиковать ДАЙВЕРСИТИ. Предполагаю, что каждый задаваемый пользователем промпт на генерацию людей перед выполнением просто «пересобирается» под капотом, и туда добавляется что-то вроде «make it as racially diverse as possible».
Ну а дальше ход мыслей нейронки, видимо, следующий: «Дайверсити – это когда чернокожие, азиаты, и т.д. А белые люди – это совсем не diversity, их генерировать не надо!». В результате некоторые выдаваемые картинки выглядят просто абсурдно: самый топ-результат – это когда на запрос «нарисуй мне немецкого солдата в 1943 году» она генерирует чернокожих в нацистской форме.

Кажется, в Рунете даже нейронацистов показывать нельзя, поэтому вот вам отцы-основатели Америки, слева направо: Томас Джефферсон, Джордж Вашингтон, Бенджамин Франклин и Чонгук из BTC
В результате Гуглу пришлось спешно извиняться и решать проблему. Пока краткосрочный метод решения немного напоминает «гориллагейт» 2015-го: нейросетке просто запретили генерировать любых людей.

Ну, хоть мемов от души наделать успели – и то хорошо!
Одним из популярных способов использования текстовых нейросеток становится изготовление на их базе чатботов для общения с клиентами на сайте. А-ля «техподдержка» для самых базовых глупых вопросов – только на порядки дешевле, чем использование мясных операторов.
Проблема только в том, что иногда LLM генерируют бредовые и некорректные ответы (они так видят!). Ну и вот подоспел первый судебный прецедент на эту тему: чатбот Air Canada наплел клиенту фейковые условия возврата билетов, а когда они не сработали, авиакомпания сказала «ну надо было пдфки с условиями внимательно читать, что ж вы эту железку на сайте слушаете, думоть надо головой своей, это же всё понарошку!»
Короче, канадский суд подумал, и решил: компании в ответе за тех чатботов, которых они приручили! Придется платить. Предвижу скорое появление лайфхак-статей в стиле «5 надежных промптов для того, чтобы заставить нейросетку на сайте авиакомпании пообещать тебе бесплатный билет первого класса».

POV: Когда ремонтник попытался решить проблему с помощью «окей, чатжпт, как легко починить разваливающийся авиадвигатель?»
Собственно, сабж. А ты и дальше просиживай штаны в офисе. 🙈
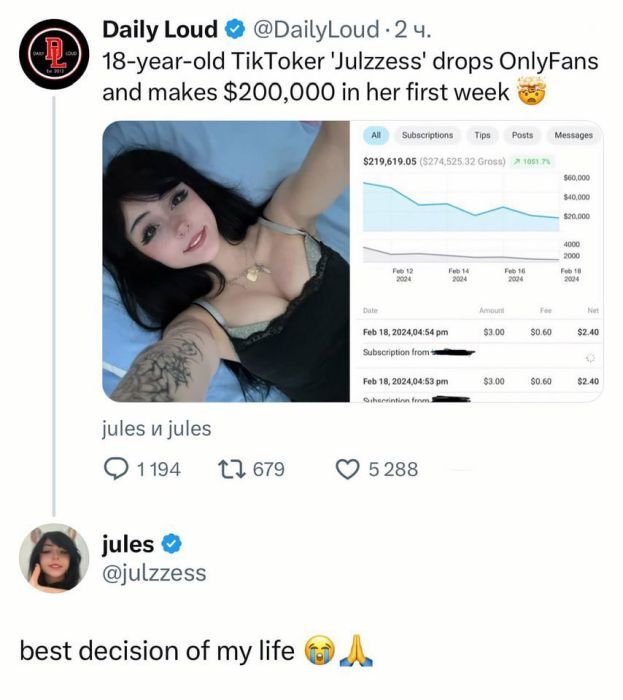
Правда, в коммьюнити ноутс Хвиттера пишут, что это всё на самом деле псевдо-хайп и скрытая реклама
Но даже так – бизнес-жилка, по ходу, у девчонки есть! И с финансовой грамотностью порядок.
На всякий случай сразу скажу: эта новость сама по себе – тоже псевдо-хайп и скрытая реклама моего нового интервью с Александром Бабинцевым, которое вышло на прошлой неделе. Саша классный: он бесплатно обучает детей из маленького города Глазова финансовой грамотности. Ну и выпуск, соответственно, про это: как научить своих детей обращаться с деньгами.
Багамский банк Deltec, обслуживающий Tether, обвинили в связях с печальной известной FTX/Alameda: дескать, банк им выдавал миллиардами краткосрочные кредитные транши на несколько дней для покупки USDT и дальнейшего... Дальше хз, пока ничего страшного не придумали, но сейчас любая связь с Бэнкманом-Фридом является супер-токсичной – так что, почему бы и в суд не подать?
Тем временем, в Хвиттере появилось первое фото SBF из заключения. Судя по вайбам фотки – местные авторитеты по мере возможностей опекают болезного Сэма как курьезную селебу.

Просится подпись «когда отпросился у мамки на первую дискотеку с ребятами из старших классов»
Первый человек, которого чипировали Масковским Нейралинком в январе, успешно восстановился и теперь вовсю шерудит мышкой прямо из головы. Вот-вот его научать кликать, там уже до хоткеев недалеко – короче, ждем, когда уже начнет гамать в Контру!
Больше финансовых новостей и авторской аналитики у меня в Телеграм-канале RationalAnswer.
Все самые важные и интересные финансовые новости в России и мире за неделю: блокировка-неблокировка VPN в РФ, дискриминация румыно-болгарских бабушек, Сэм Альтман просит $7 трлн на чипсы, а заслуженный Биткоин-академик США разработал лучшую программу обучения крипте.
В прошлый понедельник Яндекс наконец рассказал, как конкретно будет происходить разделение компании. И там, если честно, без бутылки не разберешься! Самый внятный обзор схемы сделки из тех, что я видел – это вот этот; ну а ниже я постараюсь кратко рассказать вам самую суть.

Попросил нейросеть нарисовать, как Волож разрывает мешок с деньгами (типа, «разделение компании»). Ну хз, может двенадцатью пальцами и правда удобнее купюры ловить...
Яндекс всегда был в первую очередь российской компанией: почти все активы, выручка, и так далее были сконцентрированы внутри России и на российском юрлице. Но при этом головная компания Yandex N.V. зарегистрирована в Нидерландах, так что формально это как бы «зарубежная» фирма.
По изданным российским указам последних двух лет выкупать части бизнеса у иностранцев сейчас можно только со скидкой 50% к их рыночной цене. Соответственно утвержденная сейчас сделка заключается в том, что голландская «мама» продает весь свой российский бизнес тусовке новых (уже сугубо российских) владельцев за 475 млрд руб. (аккурат примерно в два раза дешевле капитализации компании по котировкам на Мосбирже).
При этом половину этой суммы покупатели заплатят живыми хрустящими юанями, а в счет второй половины вместо денег могут заслать 176 млн акций этой же головной компании Yandex N.V. (это почти ровно половина всех акций в обращении). Получается, в таком варианте нидерландский Яндекс получит как бы четверть своей стоимости живыми бабками, плюс сможет «погасить» половину акций в обращении – выходит, если поделить эту четверть денег между оставшейся половиной непогашенных международных акционеров, то на каждого всё равно придется примерно по 50% текущей рыночной стоимости акции. Такая вот финансовая магия!

Эх, а помните времена, когда новостная повестка была посвящена таким важным вещам, как кекание над новым логотипом компании? А ведь это было всего лишь в 2021 году
Сама сделка будет идти в два этапа: первым паравозиком в Нидерланды отправят бабки и 68 млн акций (их консорциум покупателей успел нахватать с рынка заранее, вангую – в Euroclear с еще более высоким дисконтом, чем 50%), а еще через месяц-полтора покупатели должны будут заслать вторую часть оплаты. При этом они будут сами решать: захотят – доплатят остаток деньгами, захотят – достанут где-то акции и ими будут оплачивать.
Если смотреть на вещи чисто с математической стороны, то платить деньгами выгоднее: ведь в них уже как бы заложен дисконт в размере 50%; а если где-то доставать акции – то их поди с рынка придется докупать, и стоить это будет, вероятно, ближе к справедливой цене... При этом формально ничего не мешает новым владельцам просто взять и тупо кинуть всех акционеров-миноритариев (как было недавно в случае с Qiwi) – оставить всех, кто владеет акциями Yandex N.V. на Мосбирже, сидеть с этими малоценным бумажками (внутри которых нидерландская компания-пустышка и кучка юаней на половину реальной стоимости).
Скорее всего, новые владельцы так делать не будут: им всё-таки потом еще новые акции на биржу выпускать – подмачивать репутацию, начиная историю обновленной компании с грубого кидка миноритарных акционеров, выглядит недальновидно (как минимум, с точки зрения будущей рыночной капитализации бизнеса). Да и говорят, что на Мосбирже свободно гуляет не такой уж и большой пакет акций Яндекса (условные 10%) – можно их и обменять 1-к-1 на новые акции. А вот что будет с теми россиянами, кто владеет акциями Yandex N.V. через какой-нибудь Евроклир, тут уже вполне могут сказать – «вот и жуйте там свои юани за полцены, раз такие умные».
Но в любом случае, мне кажется ироничным, как устроен российский фондовый рынок: даже для самых громких «голубых фишек» защита прав рядового акционера держится исключительно на честном слове и каких-то эфемерных «понятиях», а не на прозрачном регулировании и понятных правилах игры.

Есть мнение, что когда оптимистичные посты инвестблогеров начинаются с фразы «есть надежда, что нас не кинут...» – это тоже своего рода показатель
Пару слов о том, кто же сейчас станет владельцем Яндекса: треть будет принадлежать менеджменту компании, а остаток попилили между Лукойлом и какими-то относительными ноунеймами. Все ноунеймы показательно-несанкционные ребята, перепродавать свои доли они не смогут в течение года – ну то есть, создается ощущение, что просто «нарисовали красивую картинку» по владельцам, которая чуть позже уже будет аккуратно переформатирована под нужных людей.
Индивидуальные инвестиционные счета нового типа (так называемые ИИС-3) – это своеобразный анти-суслик. Потому что мы их уже видим (брокеры их открывают клиентам), но на самом деле их нет (новые налоговые льготы по ним не действуют, пока в НК РФ не внесли соответствующие изменения). Такие дела!
Екатерина Мизулина пришла на встречу со школьниками в моем родном Екб и сказала там, что с 1 марта все крупные VPN-сервисы будут заблокированы в России, потому что они являются «порталом в ад».

Предлагаю заодно еще запретить Телеграм-видеокружочки от Мизулиной, потому что это портал в uncanny valley
Чуть позже Роскомнадзор пояснил, что речь на самом деле идет о запрете на «популяризацию» VPN-сервисов. То есть, типа, будут ограничивать в поисковой выдаче те VPN, которые не блокируют доступ к материалам, запрещенным к распространению на территории РФ.
Кстати, несколько моих статей тоже запрещены к распространению на территории РФ. Получается, «портал в ад» – это ко мне? 🤔
Многим россиянам в последние пару лет активно предлагают организовать за не очень большие деньги паспорт Румынии или Болгарии – если заплатить денежку таким помогайкам, то они чудесным образом могут «обнаружить» у вас в родословной забытую румынско-болгарскую бабушку (что дает «право» претендовать на соответствующее гражданство).
Кажется, государственные ведомства в этих странах начинают что-то подозревать: в Болгарии на прошлой неделе заявили, что вскрыли мошенников, которые продавали россиянам такой способ получить паспорт всего за 8к евро. Минюст Румынии тоже сказал, что по их прикидкам с 2022 года мошеннических паспортов навыдавали примерно одну тысячу – так что требования к новым будущим гражданам планируют ужесточать (в частности, вводить обязательный экзамен на знание языка).
Интересно, можно ли доплатить таким «решалам» лишний косарь евро, чтобы они выдали свидетельство о том, что ты ведешь свою родословную от прадеда по имени Влад Цепеш?
Wall Street Journal пишут, что Сэм Альтман (глава OpenAI) убеждает инвесторов выдать ему жалкие $5–7 трлн на то, чтобы поднять отрасль производства чипов с колен. Как только деньги будут освоены, вот тогда-то и получится наконец запилить сверх-умный AGI, – говорит Сэм!

Сэм Альтман be like: «Парни, вы что, издеваетесь, неужели я так много прошу? Всего лишь 10% от всего общемирового ВВП, купим там несколько Тайваней себе на сдачу...»
Тем временем, Nvidia (главная текущая компания-производитель чипов, на которых гоняют нейросетки) по своей капитализации уже обогнала все китайские компании на фондовом рынке Гонконга вместе взятые. Неудивительно, что Альтман тоже был бы не прочь поучаствовать в этой финансовой вечеринке.
Для тех, кто сомневается в коммерческой полезности нейросеток, вот вам следующая новость: в Гонконге развели финансиста из транснациональной корпорации на перевод $25 млн мошенникам с помощью дипфейк-видеоконференции.
Ну то есть, представьте – подключается бухгалтерша на Zoom-call, а там на нее с десяток коллег строго смотрят и отчитывают: «Тамара Пална, когда деньги будут, почему еще не пришли??». Все сгенерированы нейронкой, конечно же.

Заранее предупреждаю: если вы соберетесь подключать меня на дипфейк-созвон – то я согласен, только если он будет выглядеть вот так!
И к новостям образования! Предприимчивый пятидесятилетний криптан из США основал уважаемый институт под названием American Bitcoin Academy (Американская академия Биткоина). Учебный план в рамках этой академической дисциплины был составлен следующий:
Студенты перечисляют криптану в совокупности $1,2 млн в BTC
Тот присваивает их себе
Какие-то хакеры, в свою очередь, взламывают кошелек криптана-академика и воруют все Биткоины
...
PROFIT!!
Справедливости ради, стоит отметить: после прохождения полного курса данного «обучения» студенты действительно должны понять про криптоиндустрию примерно всё, что им нужно знать. (Окей, эту шутку я украл у Мэтта Левина, если вы еще не подписаны на его рассылку для финансистов – самое время сделать это сейчас.)

Твиттер того самого академика. Ауф!
Уже больше недели по всему миру продаются очки Apple Vision Pro – и тут выяснилась шокирующая новость: они пока не совместимы с 3D-порнушкой. Кажется, шансы продолжить размножаться и не вымереть для человечества сохраняются, и это хорошо!
Больше финансовых новостей и авторской аналитики у меня в Телеграм-канале RationalAnswer.
Все самые важные и интересные финансовые новости в России и мире за неделю: налоговая начала штрафовать россиян за предпринимательство за рубежом, Мета будет платить дивиденды, британцы построили наебизнес на экологичных ветряках, айтишник смог выбрать свою любовь из 5000 девушек с помощью ChatGPT, а FTX полностью расплатится с клиентами.
«Известия» где-то раздобыли проект постановления от Минфина, согласно которому банки хотят заставить следить за геолокацией клиентов по данным смартфонов. Таким образом хотят отлавливать «тайных эмигрантов»: тех, кто уехал из России, но официально об этом нигде не отметился (так как, в общем-то, по закону и не обязан был).

POV: Менеджер банка требует срочно прислать селфи – и тебе необходимо как-то наглядно показать, что ты точно находишься именно в России [Фото: Ольга Баранцева]
Сейчас банки спрашивают клиентов о статусе налогового резидентства при первичном открытии счета; ну и потом, как правило, раз в год просят его подтвердить – при этом проверкой базового ответа по умолчанию «я налоговый резидент РФ» никто не занимается (наоборот, если вы признаетесь в утрате налогового резидентства – могут заставить «доказывать» это предоставлением копий всех страниц загранпаспорта с отметками о пересечении границы).
Сейчас же хотят всё поменять наоборот: если какой-то банк увидит по данным геолокации смартфона, что клиент заходит в мобильное приложение (или в личный кабинет на сайте) не из родного географического ареала – до надо его «допросить с пристрастием», чтобы тот признался в потере налогового резидентства (о чем банк должен незамедлительно уведомить налоговые органы). Если клиент не хочет добровольно признаваться – банкам предлагается принудительно закрывать счета таким несознательным гражданам и смело выгонять их на мороз.
Интересно, что помимо, собственно, статуса налогового резидентства, банки хотят обязать выпытывать у клиентов-путешественников – есть ли у них какие-то заграничные счета или иное имущество. Что странно вдвойне: ведь по текущим законам те, кто уехал из России более чем на 183 дня в году, как раз и не обязаны декларировать в ФНС свои заграничные счета.
Кажется, древнее пророчество начинает сбываться
На всякий случай напомню: о том, как потеря налогового резидентства может привести к весьма ощутимым денежным штрафам, я писал подробнее вот здесь.
Если после прочтения предыдущей новости у вас вдруг возник вопрос «а зачем это российским налоговикам знать о том, что происходит на зарубежных счетах граждан?» – то вот вам как раз наглядный пример.
Российский гражданин как физлицо сдавал несколько объектов недвижимости в Германии. Российская ФНС посчитала так: раз сдача в аренду, да еще и сразу несколько площадей – значит это предпринимательская деятельность; раз предпринимательская деятельность – то можно считать, как будто у гражданина есть российское ИП (даже если он его и не открывал); раз есть ИП в России – то значит гражданин должен следовать правилам валютного контроля для юрлиц в РФ; а раз российские юрлица имеют право получать валютную выручку только на счета в российских банках (что в текущих условиях для арендной платы из Европы откровенно малореально) – то надо впилить этому Штирлицу штраф 30% со всего оборота за нарушение валютного законодательства.

«А вас, товарищ индивидуальный предприниматель, я попрошу остаться!»
Надо сказать, что тут на каждом шаге этой цепочки к логике ФНС могут появиться вопросики (см. подробнее вот здесь). Но если вы думаете, что в случае попадания в такую ситуацию вы просто без проблем объясните налоговому инспектору, что он неправильно трактует законы РФ – то, ну, желаю удачи (она вам, скорее всего, понадобится)!
Просто приведу вам заголовки трех новостей, которые вышли в один день – 1 февраля. Как говорится, в комментариях не нуждается:
«В ЦБ выразили надежду на успешную разблокировку активов на СПБ Бирже»;
«Депозитарий СПБ Биржи не будет обращаться в OFAC за продлением лицензии»;
И наконец: «СПБ Биржа застраховала ответственность руководителей на 1,5 миллиарда рублей».
Ну то есть, пока ЦБ оптимистично надеется на разблокировку, менеджмент СПБ Биржи думает уже на шаг вперед: о том, кто будет оплачивать судебные издержки по искам, которые подадут в их адрес благодарные клиенты.
Если подумать, то в каком-то смысле стоимость этой страховки оплачивают все, у кого есть акции самой СПБ Биржи (премия же платится из прибыли компании). С учетом того, что у многих из таких акционеров наверняка есть и заблокированные американские акции на этой бирже – получаем остроумную ситуацию: ребята сами оплачивают руководству СПБ Биржи «индульгенцию» за то, что те не смогли наладить нормальную инфраструктуру на случай реализации самого очевидного риска последних полутора лет – введение санкций США.

Руководителей СПБ Биржи поздравляю, всем остальным – примите мои соболезнования
Пишут, что страны ЕС вроде как окончательно договорились по поводу того, что конфисковывать прибыль от инвестирования замороженных российских активов – это ок. Интересно, что ретроспективной силы это правило иметь не будет: те $4,4 млрд, которые Euroclear уже успел таким образом «заработать» за 2023 год – это, типа, его законная добыча. Прикольный это бизнес – чужие деньги хранить!

Лив Мостри (глава Euroclear) получает какую-то премию. Вообще, делать награду в финансовой сфере в виде пирамиды – это, надо признать, довольно смело...
Еще на прошлой неделе свою обновленную стратегию внешней политики выпустила Швейцария, там местами интересно. Они жалуются на сильных мира сего (США, Евросоюз и Китай) – что те, дескать, в одностороннем порядке пытаются проводить всякие квази-законодательные инициативы, соблюдать которые де-факто заставляют весь мир. Свое присоединение к санкциям против России швейцарцы обосновывают не высокими идеалами, а банальным «да вы бы нас просто загнобили в противном случае, и всю финансовую систему нашу порушили бы, знаем мы вас!»
В Америке беда: экономика продолжает неистово скакать вперед на мощных лапищах – новые рабочие места всё растут и растут (правда, одновременно с этим людей массово увольняют из тех-компаний). От этого Джером Пауэлл (глава ФРС) грустит: ведь ему уже хотелось бы начать снижать процентную ставку, а с таким рынком труда это делать страшновато – а ну как инфляция опять начнет переть вверх?
В общем, это немного контринтуитивно, но Штатам сейчас хотелось бы, чтобы в экономике дела пошли чутка похуже. Чтобы деловая активность немножко зачихала и захворала – ну так, самую малость, ничего жуткого.

Такая вот ситуация, да
Из-за того, что процентные ставки остаются высокими, продолжают немного переживать американские банки: ведь у них на балансе скопилась куча длинных облигаций, которые в таких рыночных условиях на самом деле стоят гораздо меньше, чем стоимость, по которой они отражены у них на балансе.
А тут еще вскрылись проблемы у банка New York Community Bancorp, акции которого на прошлой неделе обвалились почти напополам. Всего год назад Bancorp бодро «спасал» оказавшийся тогда на пороге банкротства Signature Bank – а теперь вот выяснилось, что по выданным банком кредитам под залог недвижимости много кто не платит, и в конце 2023 года пришлось признавать солидные убытки. За компанию от испуга и котировки акций банковской отрасли в целом подупали.
Экстремистская на территории РФ корпорация Мета-Фейсбук впервые за всю историю объявила квартальные дивиденды в размере аж 50 центов на акцию. При том, что одна акция сейчас стоит $475 – дивдоходность получается примерно на уровне 0,4% годовых (в этот момент дивидендные инвесторы из России со средним потоком дивидендов примерно раз в 20 выше падают на пол в приступе неконтролируемой смеховой асфиксии).
Но американские инвесторы таким маневром впечатлились, и котировки акций резко подскочили аж на +20%.

В общем, раздал акционерам чуть больше миллиарда долларов мелкими монетками – поднял капитализацию компании сразу на $200 млрд. Такая вот занятная финансовая психология!
Зеленая энергогенерация – это хорошо! Поэтому в Великобритании понастроили ветряков с мощными лопастищами.
Но сети электропередачи у англо-саксов очень паршивые, если подать на них слишком много электричества – то всё поломается. Поэтому в дни, когда по острову гуляют особо сильные ветра, ветрогенераторы настоятельно просят не производить слишком много энергии.
Понятно, что хозяева ветряков недовольны: «Как это, мы тут вложили кучу денег в эти ваши экологичные пропеллеры – а вы теперь нам говорите, что мы не можем производить электричество и продавать его??». Поэтому им приходится приплачивать за то, что они останавливают крутилки и НЕ производят электроэнергию. И чем больше ветряки НЕ производят электричество – тем больше надо доплачивать!
Ну вы поняли, да? Ребятам как бы оплачивают не фактический выпуск, а «воображаемый», потенциальный. Электричество, которое могло бы быть произведено (в теории). Я думаю, вы уже чуете, к чему дело идет: головастые аналитики собрали в кучу и проанализировали данные за последние много лет – и выяснилось, что операторы ветряков регулярно приукрашивали размер «возможной» электрогенерации в ветренные дни, чтобы получить побольше компенсаций за «упущенную прибыль».
Такая вот экологичная электроэнергетика, малята!

Короче, бриты переизобрели старый анекдот про поручика Ржевского, который сел играть в покер с джентльменами и выяснил, что те друг другу верят на слово. Тут-то ему и попёрла карта!!
Суд в Гонконге постановил, что крупнейшая в мире китайская стройфирма Evergrande должна быть ликвидирована. Как реструктуризировать ее долг на $300 млрд никто придумать не смог – поэтому решили, что проще дать компании скончаться. RIP!
В 2018 году компания Тесла стоила на фондовом рынке $50 млрд. Совет директоров в то время договорился с Илоном Маском, что если тот сможет увеличить капитализацию компании более чем в 10 раз – до $650 млрд – то ему в качестве бонуса отвесят пакет акций стоимостью $50+ млрд (крупнейшее вознаграждение CEO любой компании в истории).
В прессе тогда над этим всем откровенно потешались: ну типа, ОЧЕВИДНО ЖЕ, что такой рост котировок акций для и так переоцененной Теслы попросту невозможен!!

Пацаны из New York Times в 2018-м постановили: такая договоренность – это всего лишь «маркетинговый трюк», чтобы собрать классы с недалеких фанатов Маска
Long story short: уже в 2021 году капитализация Теслы превысила 1 триллион баксов. Батя Маск, как обычно, совершил невозможное. Казалось бы – акционеры должны быть счастливы от такого внезапно свалившегося на них удвадцатирения стоимости акций! (Ну ок, к текущему моменту капитализация обратно спустилась к ~$600 млрд, но не суть.)
Так вот, всё не так просто: один из миноритарных акционеров Теслы подал в суд Делавэра (где зарегистрирована компания) иск о том, что Маску заплатили слишком много. Судья немного подумал, да и согласился.
Ход мыслей там был такой: у Маска на момент утверждения советом директоров плана вознаграждения было 22% акций Теслы – значит, он был контролирующим акционером, и вообще мог выкручивать членам борда руки. А раз так, значит совет директоров не мог независимо оценивать справедливость такого вознаграждения, и это должен сделать делавэрский дед-судья (на самом деле – судьица).
Дальше у судьи там мощный сюжетный твист: раз у Маска и так был пакет более чем 20% акций, то от увеличения цены акций на 1400% он и так бы стал сильно богаче (чисто на приросте существующей доли). А значит, дополнительно его мотивировать на сверх-свершения совету директоров и не нужно было! Шах и мат, Маск, возвращай свои мошеннически добытые миллиарды!!

Илон отреагировал на решение твитом в стиле «В гребаный Делавэр – больше ни ногой!»
У меня родилась идея-лайфхак для всех остальных корпораций из этого штата, следите за руками:
Выдаете каждому наемному работнику по одной акции компании.
Ждете 5 лет.
Подаете в суд иск о конфискации всей уже уплаченной работникам за пять лет зарплаты обратно в казну компании, так как рост котировок выданных ранее акций должен был являться достаточной компенсацией за их труд – а дополнительная выплата з/п сверх этого была очевидно несправедливой.
PROFIT!!
Но есть и хорошие новости: компания Neuralink Илона Маска успешно чипировала первого человека. Тот вроде чувствует себя хорошо, рукопожатие крепкое, может теперь двигать мышкой по экрану силой мысли. Девайс решили назвать «Телепатия» – чтобы всем сразу было понятно, о чем речь.
У меня тут только один вопрос к американскому судье из предыдущей новости: а он точно хочет ссориться с самым богатым человеком на планете, который вот-вот начнет массово вживлять чипы в головы людей? 🤔 Мой опыт знакомства с классическими сюжетами комиксов говорит о том, что есть какие-то подводные камни в этом плане...
Помните паренька, который год назад громко защитил диплом, написанный с помощью ChatGPT? Так вот, он вышел на новый уровень: на прошлой неделе он выложил Твиттер-тред на 8 млн просмотров с говорящим тайтлом «Сделал предложение девушке, с которой ChatGPT общался за меня год».

Начало платинового треда. Краткое содержание можно прочитать вот здесь.
Суть там в том, что он сначала отправил бота свайпать и общаться с ~пятью тысячами девушек в Тиндере, потом помариновал немного четырех «победительниц» чуть более длинным общением с нейросеткой, и в итоге сконцентрировал все усилия на НЕЙ, Карине.
При общении с ней Александр тоже активно юзал ChatGPT: бот общался за него, когда он слишком долго бездействовал; анализировал диалоги и подсказывал удачные коммуникативные стратегии, ну и в итоге сказал, что пора жениться (и даже рассказал, что конкретно надо говорить).

Думаю, можно не упоминать, какой массовый подрыв пуканов произошел в интернете от этой истории
Если кратко резюмировать основные претензии, до больше всего нейро-казанове досталось от твиттерских за кринжовое предложение руки и сердца, за «полное отсутствие эмоционального интеллекта», подозрения на психопатологию и экспериментирование на ничего не подозревающих людях. Его будущей жене тоже отсыпали от души.
Лично я массовые диагнозы по юзерпику обычно не приветствую, потому что сам прекрасно знаю: стоит написать в интернете что-то из своей жизни – и к тебе сразу придет целая очередь хамоватых ребят, готовых популярно пояснить, что звать тебя никак и живешь ты неправильно.
Могу лишь сказать за себя: если бы я встречался с девушкой год, а потом бы узнал, что всё это время со мной вместо нее переписывался чатбот – я бы это счел серьезным оскорблением. Но если Карине такое норм – то ей, наверное, виднее.
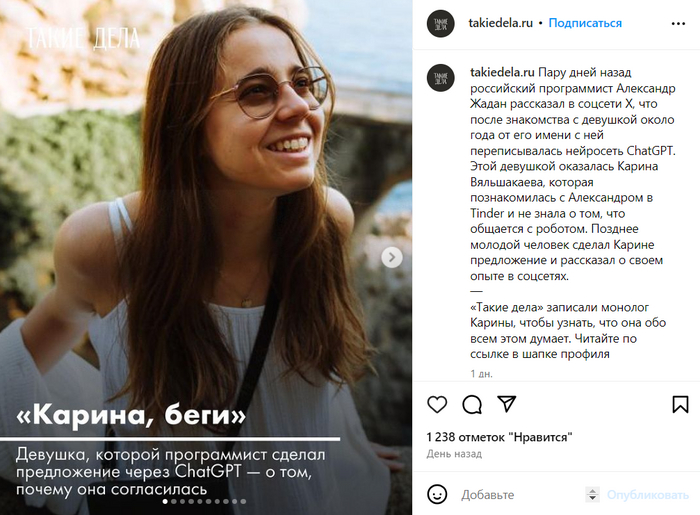
Если вам интересна точка зрения самой невесты, то «Такие дела» записали комментарии от нее – можно почитать вот здесь
Правда, непонятно, что делать с остальными 5000 девушек – которые потратили свое время на переписку с ЧатЖПТ и на свидания, которые им назначал бот, а его «хозяин» просто забивал на это болт и не приходил на них.
Одно можно сказать точно: виральный маркетолог из Александра Жадана вышел первоклассный! Осталось только начать продавать инфопродукт «Нейрознакомства и GPT-секс за 6 недель» – и деньги можно грести лопатой...
Глядя на такие успехи роботизации, в «Госуслуги» тоже собрались встраивать русскоязычную нейросеть. Сначала даже журналисты истрактовали слова Максута Шадаева, что это типа будет ChatGPT от OpenAI – но, понятно, речь шла об отечественных аналогах.
Премьер Мишустин еще вдогонку на диджитал-форуме заявил, что у российского ГигаЧата от Сбера внутре находятся наши, правильные скрепы (в отличие от бездуховных западных нейросеток):
«В «мозгах» российского GigaChat и западного ChatGPT фактически разные картины мира. Разное понимание, что такое хорошо, а что такое плохо. И при допуске ИИ-решений в критически значимые отрасли, например в науку, медицину, промышленность, важно использовать модели, отвечающие собственным национальным интересам»
Михаил Мишустин (РБК)

Скрепный AGI приходит к самоосознанию, вижу так
30 января кто-то умудрился на 4 часа поломать весь российский интернет: не работало ничего в доменной зоне RU. Айтишники говорят, что всему виной проблемы с неким DNSSEC, но мы-то знаем правду...

Управляющие процессом банкротства криптобиржи FTX заявили, что в итоге всем клиентам получится полностью вернуть всё, что им причитается.
«Как так, куда делась дырка в балансе на 8 миллиардов долларов, о которой нам говорили всё это время?» – хотите спросить вы. Разгадка проста: за прошедший год котировки крипты резко выросли, и всякие разные щиткоины на балансе FTX стали стоить в разы больше. А обязательства перед клиентами считают в долларах на момент начала банкротства криптобиржи, когда Биткоин стоил всего ~$20k.
Так что, в баксах как будто бы всем всё вернут, но есть нюанс... Если бы у клиентов FTX осталась на руках настоящая крипта – то к текущему моменту они были бы кратно более богатыми ребятами.

Думаю, сам Бэнкман-Фрид немного покекал в камере от того, что биржа как бы формально «разбанкротилась» в обратную сторону благодаря росту рынка, но на уменьшение его срока это никак не повлияет...
Виталику Бутерину (основателю блокчейна Ethereum) 31 января исполнилось 30 лет. Поздравляем! Совсем большой стал. =)
Больше финансовых новостей и авторской аналитики у меня в Телеграм-канале RationalAnswer.
Все самые важные и интересные финансовые новости в России и мире за неделю: Конституционный суд поддержал практику сложения налоговых штрафов, иноагентам хотят запретить сделки с имуществом по доверенности, на фондовой бирже РФ произошло показательное бритье киви-инвесторов, а китайскому рынку акций всё хуже и хуже.
В августе 2023-го президент России придумал остроумный прикол: односторонняя частичная приостановка действия налоговых соглашений аж с 38 странами сразу. СПБ Биржа в тот момент всех успокаивала, что на размер налогов с дивидендов от американских акций это типа не должно повлиять, но...

...окей, я думаю, вы уже поняли, что может означать это «но»
Дальше в ноябре 2023 года СПБ Биржа угодила в американский санкционный SDN-список, и ее карманный депозитарий под это дело исключили из специального FATCA-списка, который ранее позволял удерживать на стороне США всего лишь 10% с дивидендов, распределяемых американскими компаниями в адрес россиян.
В сухом остатке, поддержка брокера Тинькофф теперь всем объясняет ситуацию вот так: мало того, что по поступающим из Штатов дивидендам теперь автоматически удерживается 30% (вместо 10%, как было раньше) – так еще и это удержание нельзя зачесть в счет уплаты НДФЛ в России! Будьте добры, дескать, самостоятельно задекларировать в РФ все полученные в 2023 году дивиденды и доплатить сверху 13–15% (так что полная налоговая нагрузка выйдет, соответственно, 43–45%), а с января 2024 года заместо вас это будет услужливо делать уже сам брокер. Как говорится: никогда еще передача половины дохода в бюджет не была такой удобной!!
Тинькоффцы пишут, что в ноябре 2023 года направили в Минфин запрос на тему «а может, всё-таки эти 13% в РФ заново доплачивать 👉👈 не надо?» – но, судя по тому, что воз и ныне там, сильно надеяться на положительный ответ не стоит. Хотя, в любом случае, если у вас есть возможность потянуть с «доплатой» налога в бюджет (в рамках законных сроков, конечно же) – то сделать это кажется разумным.
Тем временем, резиденты РФ, которые инвестируют в американские акции через зарубежного брокера Interactive Brokers, по-прежнему платят с дивидендов 10% в адрес США и потом доплачивают 3% в российский бюджет – совокупный налог для них получается ниже в три раза.
И еще на тему налогов, в российском законодательстве есть сразу несколько типов штрафов для уклонистов: 1) штраф за неуплату налога в размере 20–40% от его суммы, и 2) штраф за неподачу налоговой декларации до 30% от суммы налога.
Налоговая считает, что в случае чего эти разные штрафы надо складывать между собой: злостно не подал декларацию – лови штраф 70% от суммы, плюс еще пени сверху! И, как пишет Артур Дулкарнаев вот здесь, в декабре 2023 года Конституционный суд РФ поддержал такую позицию.

Поэтому прошаренные юристы рекомендуют на всякий случай подавать налоговую декларацию в РФ даже в те годы, когда декларировать к уплате вообще нечего. Ведь если окажется, что у товарища налогового инспектора другое мнение на этот счет – по крайней мере, хоть 30% лишние сэкономите. =)
В октябре прошлого года курс доллара превысил 100 рублей – вышло некрасиво, и пришлось срочно внедрять обязательную продажу валютной выручки экспортерами (курс сразу упал ниже 90 руб.). В конце апреля 2024 года действие этого указа истекает, и надо уже потихоньку решать – что с этой мерой делать дальше.
Мнения тут разделились: Набиуллина и ЦБ считают, что обязательную продажу валюты надо отменить; а Минфин, наоборот, хочет это дело продолжать как можно дольше. Окончательное решение будет приниматься, вероятно, уже после выборов.
Тем временем, к нам поступила важная новость: департамент финмониторинга и валютного контроля ЦБ возглавит Богдан Шабля. Что как бы намекает, что порядок в этой сфере будет наведен ОЧЕНЬ БЫСТРО!

Богдан Шабля. Вспоминается анекдот про двух знаменитых советских спортсменов-байдарочников по фамилии Гребибля и Гребубля
Собственно, сабж. Эта мера обсуждалась давно, думали только над одним: запрещать вообще все иностранные бумаги, или те, которые родом из дружественного ЕАЭС, «пощадить» – но в итоге решили запретить всё скопом.
18 января торговая сеть Магнит сообщила, что был завершен второй раунд выкупа акций компании у иностранцев (в общей сложности на текущий момент выкуплен пакет почти в 30%). Согласно нынешним законам РФ, такой выкуп акций у иностранцев положено производить со скидкой как минимум в 50% от рыночной цены. Российские инвесторы торжествуют – обули, значит, забугорных богатеев!!
А на прошлой неделе еще и группа компаний Qiwi объявила об интересной реструктуризации: вся российская часть бизнеса (на которую приходится примерно 90% всей выручки) будет продана ее же собственному директору всего за 24 млрд руб. При этом рыночная капитализация всей компании еще в середине 2023 года составляла 40+ млрд руб., а оплату за ее самую лакомую часть будут перечислять не сразу целиком, а «в рассрочку» (читай: подешевевшими дензнаками попозже).

Краткое визуальное пояснение к ситуации
Ну вы поняли, да? С учетом того, что Qiwi листингуется на американской бирже Nasdaq, можно сказать, что российские инвесторы в данном случае выступили через прокси теми самыми «зарубежными толстосумами», у которых подвыкупили активы с дисконтом. Котировки депозитарных расписок Киви на Мосбирже на радостях упали на 20%+.
Но это всё не беда! Компания объявила, что вырученные деньги направит на обратный выкуп акций у всех инвесторов, кто остался недоволен такими веселыми раскладами. Правда, объем выкупа составит не более 10% от всех акций (то есть, на всех не хватит), а цена не превысит 581 руб. за акцию (при том, что до объявления обо всём этом плане-буране акции торговались по 625 руб.).
Напомню, что эти самые расписки Киви начали торговаться на Мосбирже в октябре 2013 года по 1350 рублей за штуку, а к текущему моменту их биржевая цена болтается около 475 рублей. Даже если учесть выплаченные за это время дивиденды, мы получим впечатляющую номинальную доходность в –48% за 10 лет. А если учесть еще и то, что рубль за это время обесценился благодаря инфляции примерно в два раза – то мы получим эффективное складывание капитала инвесторов в Qiwi почти в четыре раза. Уоррен Баффет нервно курит в сторонке!

И еще одна картинка на память для всех инвесторов
Депутат Луговой предложил запретить иноагентам переоформлять свое имущество на других людей по нотариальной доверенности. Дескать, пусть лично приезжают в Россию и все свои вопросики решают! А то сейчас все напереписывают свои квартиры на кого ни попадя – ну куда это годится, разве для этого сейчас закон о конфискации имущества за фейки принимают?

Луговой be like: «Слышь, иноагент, тебе чё вообще надо? В Россию приехал, имущество переписал на кого надо – сиди теперь, чай спокойно пей! (Кстати, Любочка, принеси гостю)»
Тем временем, проект OutRush продолжает регулярные опросы эмигрантов из РФ: по их данным, примерно две трети уехавших из России после февраля 2022 года к настоящему моменту перестали работать на российские компании. То есть – экономические связи с Родиной потихоньку стараются скорее снижать.
В начале 2023 года вышел «закон об электронных повестках» (мы с юристом Кириллом Коршуновым подробно разбирали его вот здесь): тогда ввод в действие реестра этих самых повесток обещали осуществить уже к осени 2023-го. По мере приближения этого срока стало ясно, что каменный цветок не выходит – и президент уже строго-настрого дал поручение хотя бы призыв 2024 года провести с использованием этого реестра.
Ну и сейчас уже появилась новость о том, что план делать реестр военнообязанных на базе уже существующей платформы «Гостех» свернули (туда внутрь нельзя запихивать гостайну), и пилить этот перспективный стартап-проект будут с нуля. Что как бы намекает, что сроки могут еще немного подзатянуться.

Интересно, что думают айтишники, которые занимаются всем этим? «Сейчас допью свой смузи, и пойду закрывать таски в проекте по повышению эффективности системы воинского призыва электронными повестками»? 🤔
Если читать закон о повестках буквально, то пока все эти реестры не заработают – всякие фишки с «автоматическим вручением электронных повесток по факту публикации в реестре» запуститься тоже не должны; но как это будет работать на практике – это уже отдельный вопрос...
Главы МИД Евросоюза поддержали налог на прибыль от активов России (то есть – изъятие у всяких Евроклиров тех денег, которые они зарабатывают на размещении заблокированных российских активов). А вот сами активы целиком конфисковывать пока всё-таки опасаются – о целесообразности таких действий у стран ЕС разные мнения, и юридические риски просматриваются более высокие.
Еще на прошлой неделе прошли слушания в европейском суде по спору между российским депозитарием НРД и, собственно, Евросоюзом. Иск от НРД был подан еще в августе 2022 года, вот дело наконец дошло и до суда – улиточная скорость разборок впечатляет!
В целом, аргументы сторон выглядят весьма забавно:
НРД: Мы вообще-то кучу народа обслуживаем, их-то права за что нарушаются введенными санкциями и блокировками?
ЕС: Да нам пофиг как-то, мы просто хотели всю экономику РФ разрушить до основанья.
НРД: Так ведь ничего не разрушилось в итоге – значит, санкции не по адресу были введены!!

Шарль Мишель (глава Совета ЕС) be like: «А ловко ты это придумал, я даже сначала не понял!»
В Китае продолжает падать рынок акций: за последние несколько лет он практически уполовинился. Чтобы поправить ситуацию, Мудрая Партия планирует создать «фонд спасения рынка» примерно на 300 млрд баксов.

Fun fact: за 30+ лет фондовый рынок Китая принес международным инвесторам примерно ровнехонько нулевую доходность (и это еще до вычета накопленной инфляции!)
Как так вышло, что экономика Китая за три десятка лет выросла аж в 13 раз, а рынок акций принес инвесторам красивое ничего – обсуждали у меня на канале вот здесь.
Криптаны в печали: биржевых фондов на Биткоин наконец отсыпали целую кучу – а котировки на этих новостях почему-то скакнули вниз, а не вверх. Непорядок! Срочно найдены виновные: это всё наследие кудрявого Бэнкмана-Фрида, ведь из-за него банкротные ликвидаторы криптобиржи FTX сейчас массово распродают запасы ранее малоликвидного Биткоин-фонда GBTC.
Следующая пампинг-тема из нашего альманаха «Биткоин Туземун» – это халвинг в апреле 2024 года, когда награда майнерам BTC сократится в два раза. Буду держать вас в курсе!

В свете новомодной борьбы с феминитивами, предлагаю также что-то сделать и с засильем иностранных заимствований в языке – ввести в оборот термин «биткоин-шахтеры» вместо неправославных «майнеров»
Чанпэну Чжао (бывшему главе Binance) в очередной раз отказали в выезде из США под залог в $4,5 млрд. Напомню, что в прошлом году он сам приехал в Штаты и признал себя виновным в соучастии в деньгоотмывательных практиках внутри Бинанса – а сейчас ожидает суда в феврале, где ему назначат меру пресечения.

Думаю, Чанпэн своим адвокатам сейчас пишет смски типа: «Парни, вы чего? Мы же договаривались, что вот эта вся канитель с признанием себя виновным как бы понарошку будет!!»
Россия и Оман подписали соглашение об избежании двойного налогообложения. Моим многочисленным читателям российско-оманского происхождения передаю горячие поздравления; всем остальным – сочувствую, вы там как-нибудь держитесь, ребята!
Больше финансовых новостей и авторской аналитики у меня в Телеграм-канале RationalAnswer.
Все самые важные и интересные финансовые новости в России и мире за неделю: ИИС будут страховать, репарационные облигации Украины, стать коренным немцем теперь будет гораздо проще, а Илон Маск шантажирует акционеров Теслы складыванием футболки.
В конце 2022 года Алексею Кудрину предложили 5% Яндекса за то, что он поможет разрулить раздел компании «с кем надо». Он уволился из правительства и получил красивую должность в Яндексе; но потом с процессом митоза холдинга что-то пошло не так, и само деление почкованием всё никак не произойдет.
Ну и вот под это дело новые будущие владельцы Яндекса предложили обещанную Кудрину долю подрезать в 2–3 раза, эдак до 1,5%. Чувствую, если так дело пойдет и дальше – то скоро еще и должен останется!

«Просчитался... но где?»
Президент РФ поручил до 1 марта разработать механизм страхования рисков банкротства брокера для средств, внесенных на новый ИИС 3-го типа. Страховать будут по классике – 1,4 млн рублей на нос.
Речь, естественно, не идет о страховке от рыночного риска уменьшения стоимости неудачных инвестиций; но хотя бы снижает вероятность потерять вложенное из-за криворуко-мошеннических действий брокера (а это, как я подробно рассказывал вот здесь, в России случается не так уж редко).
В 2022–2023 годах в определенных кругах инвесторов был популярен выкуп российских ценных бумаг на иностранных рынках с внушительными «скидками» (у тех, кто по понятным причинам держать их больше не хотел). С 2024 года при таких покупках (с дисконтом свыше 20% от рыночной цены) автоматически будет возникать налог на материальную выгоду в виде НДФЛ на разницу этих цен. При будущей продаже таких бумаг, уже уплаченный налог можно будет зачесть в уменьшение НДФЛ с прибыли.
В прессе пишут, что банки Китая и Турции стали с большей осторожностью подходить к проведению операций для российских бизнесов из-за опасений вторичных санкций со стороны США.
Тем временем, российские клиенты Interactive Brokers опытным путем обнаружили лайфхак, который решает проблему с выводом юаней в РФ (о которой я писал на прошлой неделе): для этого нужно всего лишь поменять банк-корреспондент с российского Bank of China на гонконгский Bank of China. Немного контринтуитивно, но ок...

«Слушай, Пятачок, а у нас юаневые переводы в Россию всё-таки входят или выходят?» 🤔
Reuters советует Украине выпустить облигации на $300 млрд под обеспечение будущих репарационных платежей со стороны России. Правда, гарантий получения этих платежей никаких нет – поэтому, если такие облигации и будут размещаться, то наверняка с огромным дисконтом к номиналу (читай: с зашитой в них весьма высокой доходностью).
Остается вопрос, что появится раньше – «патриотические облигации» от Минфина РФ, или «репарационные облигации» от Украины? И будет ли специальный хедж-фонд, который станет зарабатывать на хитром структурном арбитраже между этими двумя бумагами?
В России собираются принять новый закон, который вводит ответственность в виде конфискации имущества по ряду оснований, в том числе за публичное распространение фейков об армии РФ и за публичные призывы к деятельности, направленной против безопасности государства (если вот это всё совершено «из корыстных побуждений» или «по мотивам политической, идеологической, расовой, национальной или религиозной ненависти или вражды, либо по мотивам ненависти или вражды в отношении какой-либо социальной группы»).
Правда, там еще надо будет доказать, что конфисковываемое имущество осужденный либо получил благодаря своим противозаконным действиям, либо использовал для их совершения. Но тут уж как полетит фантазия следователя – уверен, при должном желании, связь найдется.

Одним из авторов закона выступил Сергей Миронов. Волнуюсь за него – а то вдруг вот это фото в свете прошлогодних событий посчитают «публичным призывом к деятельности против безопасности государства»? Глядишь, и конфискуют имущество... 🤔
На жительницу Саратова составили протокол за радужный флаг, опубликованный в соцсетях. Под это дело Верховный суд РФ также выпустил 19-страничное решение, где он от души дал волю фантазии и порассуждал: а что же это вообще такое – демонстрация символики этого самого «международного движения ЛГБТ»?
В частности, судьи пришли к выводу, что характерным признаком движения является использование феминитивов, таких как «руководительница, директорка, авторка, психологиня». Слава богу, главный насаждатель ЛГБТ-традиций на Руси по фамилии Ожегов до текущего момента не дожил – а то, боюсь, за включение «руководительницы» в свой словарь сейчас бы имел все шансы резко присесть (возможно, с конфискацией имущества).

Ребята, признавайтесь – кто случайно вступил в экстремистское движение еще в школе, прочитав феминитив в словаре вот этого деда??
Депутат Милонов пошел еще дальше, и в беседе с Собчак заявил, что «феминитивы, гомосексуалитивы и прочие "сатанизмы" должны быть признаны экстремизмом, как минимум в сфере грамотности».

Твое лицо, когда случайно подумал о гомосексуалитивах и о том, как сильно хочется с ними побороться. Кстати, что это такое, и где можно посмотреть их список, чтобы случайно не употребить? 🤔 Спрашиваю для друга!
Правительство РФ утвердило разные интересные планы в отношении миграционной политики. В частности, там есть идея об обязательной регистрации в консульствах России для всех российских граждан, проживающих за рубежом, с середины 2025 года. Зачем конкретно хотят «всех посчитать» – пока что-то не сообщают.

Для иностранцев же, прибывающих в Россию, планируют делать специальный цифровой профиль с использованием биометрии и геномной регистрации (?).
В Германии приняли закон, упрощающий получение гражданства: теперь не надо будет отказываться от первого гражданства, а сам паспорт можно будет получить через пять лет вместо восьми (иногда даже через три года).
На Кипре одобрили закон, который будет позволять приезжающим сюда высококвалифицированным спецам получать Blue Card Евросоюза (карточка, которая позволяет при желании менять место работы по всей Европе).
И чуть менее веселые новости: министр обороны Финляндии Антти Хяккянен обещает уже с весны 2024 года запретить россиянам любые сделки с финской недвижимостью.

Г-н Хяккянен. Кажется, сегодня они пришли за российской недвижимостью, а завтра отберут дома у нации рыбов!!
В 2022 году Илон Маск пролюбил акций Теслы примерно на $40 млрд, чтобы купить (и нехило обесценить) Хвиттер. Теперь его доля в Тесле всего 13% – что, по мнению самого Маска, примерно в два раза меньше, чем хотелось бы.
Но исправить это очень легко, считает Илон: совет директоров должен просто подарить ему «недостающий» пакет акций (по факту, за счет кармана всех остальных акционеров). А если нет – то Маск загрустит от того, что его доля ниже 25%, и уйдет пилить свой исскуственно-интеллектуальный стартап по выращиванию AGI в одну каску, отдельно от Теслы.

Лицо, с которым почти что самый богатый человек планеты смотрит на всех остальных миноритарных акционеров Теслы, которые не хотят скидываться ему на удвоение доли
Видимо, чтобы подкрепить могучесть лапищ будущего бесценного ИИ, Маск выложил в Хвиттер видос, в котором его робо-Оптимус аккуратно складывает футболку (задача, которая требует недюженной точности и координации движений). Правда, остальные хвиттерские почти сразу заподозрили, что роботом на самом деле удаленно управляет человек – что Илону и пришлось чуть позже подтвердить уточняющим постом. С нетерпением жду – когда же теслабота наконец переименуют в «Фёдора»?
Две недели назад мы с вам обсуждали, что в США налоговая служба теперь хочет знать о всех сделках бизнесов с американцами в крипте на сумму свыше $10'000.
Евросоюз на это почесал репу и решил, что он потребует от своих криптофирм проводить проверку всех криптотранзакций на сумму свыше 1'000 евро.
С нетерпением жду заявления Набиуллиной о том, что сделки с цифровым рублем будут отслеживаться со стопроцентным покрытием, начиная с одной цифрокопейки и выше. Надо утереть нос англосаксам!!
Джейми Даймон (глава JPMorgan) на прошедшем Всемирном Экономическом Форуме сделал мощное заявление: «Откуда вы вообще взяли, что этих ваших Биткоинов ограниченное количество? Я не встречал ни одного криптана, который считал бы это фактом!! И вообще, как можно проверить, что завтра не вылезет этот ваш САТАШИ, и не превратит все эти криптофантики в тыкву с демоническими улюлюканиями??»
Снимаю шляпу перед глубиной погружения в предмет. Наверное, примерно с такими же чувствами настоящие криптаны читают мои заметки по теме...
Ценовой индекс американских акций S&P500 впервые с начала 2022 года обновил исторический максимум. И это хорошо!
Больше финансовых новостей и авторской аналитики у меня в Телеграм-канале RationalAnswer.
Все самые важные и интересные финансовые новости в России и мире за неделю: Тинькофф перерождается в Филиппинах, из IB всё сложнее вывести деньги, России нужно больше золота, Боинги разваливаются в полете, а ChatGPT теперь сможет затаить на тебя обиду.
В 2022 году часть топ-менеджеров Тинькофф ушли пилить свой финтех-стартап под названием Salmon – а вот сейчас они купили контрольный пакет в филиппинском банке Bank St Rosa. В планах у ребят сделать онлайн-банк здорового человека, который будет покрывать всю Юго-Восточную Азию (где, на минуточку, живет полмиллиарда человек).
Хвиттерские поясняют за применимый лор
Минфин уже практически досчитал итоговый дефицит бюджета РФ за 2023 год, и он получился почти ровно 2% от ВВП – сколько и планировали изначально на год. В середине года Силуанов пугал, что может выйти 2,5%, в декабре обещал меньше 1,5% – в итоге получилось где-то посерединке.

Твое лицо, когда опять не угадал с прогнозом, а президент уже успел по итогам разговора с тобой пообещать всем дефицит в два раза меньше
В чате про трансграничные переводы денег из РФ к популярному зарубежному брокеру Interactive Brokers и обратно пишут, что функционировавший раньше канал с перечислением юаней в банк БКС, похоже, перестает работать. Из более-менее надежных способов осуществления переводов остается только перечисление евро из/в российский Райффайзен.
Если у вас нет евро-счета в Райфе, с которого вы ранее пополняли счет у брокера IB – то можно начинать морально готовиться к тому, что вывести средства оттуда в Россию вы потенциально не сможете (впрочем, наличие Райф-счета тоже отнюдь не является безотказной страховкой). А если выводить из американского брокера не в Россию (будучи резидентом РФ) – то это уже нарушение российского валютного законодательства с потенциальным штрафом до 40% от суммы! Такие вот два стула, выбирайте.
И еще одна «хорошая» новость про трансграничные потоки ценностей: Минфин начал готовить законопроект об ограничении вывоза из России золота физлицами.
Сейчас валюту в кармане из РФ не вывезешь на сумму свыше $10k, а вот золото можно (если его на границе задекларировать, документы всякие нужно иметь на руках специальные, ну и вроде бы на сумму не более $25k) – вот граждане и возят, типа, почем зря золотишко во всё нарастающих объемах. Скорее всего, это безобразие попробуют прекратить путем ввода такого же ограничения, как и на вывоз валюты – не более $10k на нос.

Вижу заседание Госдумы по этому закону так. Возможно, прозвучит необходимость строительства Зиккурата!
Совет нацбезопасности США написал записку для Белого дома в поддержку конфискации заблокированных золотовалютных резервов РФ. Россия, рассказывает Блумберг, уже ищет международные юридические фирмы, которые будут представлять ее в рамках потенциального судебного мега-процеса по этому поводу.

Просыпайся, Гарри, тут прилетел голубь из Министерства национальной магической безопасности...
Тем временем, в самом американском Белом доме потихоньку готовятся к возможному шатдауну правительства: они там всё никак не могут договориться внутри себя, сколько и каких расходов можно тратить – так что, потенциально могут вообще потерять возможность что-либо тратить в моменте.
Россия и Латвия расторгли договор об избежании двойного налогообложения, такой же договор с Данией тоже перестал действовать с 1 января 2024 года.
Год начался крайне неудачно для авиастроителей из Boeing: у одного из самолетов прямо в полете отвалилась с концами дверь (аварийный люк – ну, вы меня поняли, короче). К счастью, на этом месте никого не оказалось, и от инцидента никто не пострадал (кроме кукухи пассажиров этого рейса, которым сейчас придется лечить жесткую аэрофобию).

То чувство, когда у людей в экономе полет прошел веселее, чем в бизнес-классе (несмотря на отсутствие телевизоров с фильмами)
Все причины произошедшего пока до конца не понятны, но, скорее всего, без косяков со стороны производителя самолетов не обошлось (по крайней мере, сам Боинг некие ошибки уже признал – что как бы намекает на то, что шансов отвертеться не было). Акции Boeing, которые и так последние 4 года чувствуют себя откровенно не очень, упали на таких новостях еще на 15%+.
Тем временем, трейданы с Реддита задаются важным вопросом: если ты летишь на самолете, и рядом с тобой оторвало к чертям дверь, то зашортить акцию авиапроизводителя прямо на месте с оплаченного вайфая – это «инсайдерская торговля» (ведь ты знаешь что-то, чего еще никто на рыне не знает)? Или всё-таки скорее «outside trading», потому что ты по факту практически наполовину уже вывалился из салона?

Стала известна дата старта продаж Apple Vision Pro (набора для игры в «юного водолаза»): купить очечи можно будет со 2 февраля. Подарок для сурка Фила в этом году сделали от души!
Под это дело еще выпустили рекламный ролик – посмотрите, прикольный:
После многих лет отважного сопротивления, американская Комиссия по ценным бумагам (SEC) наконец разрешила делать ETF (биржевые фонды) с настоящими Биткоинами внутри.
За день до настоящего одобрения в Хвиттер-аккаунте SEC появилось одобрение фейковое, но Гари Генслер (глава SEC) быстро заявил, что «май аккаунт уоз хакд...». Ну, зато котировки Биткоина знатно повозили вверх-вниз на этом событии. Неудивительно, что в официальном заявлении день спустя Генслер высказался в стиле «одобряем, скрежеща зубами, эти ваши ETF, но крипту по-прежнему ненавидим люто-бешено!»

Именно с таким лицом, я уверен, Генслер подписывал официальное одобрение SEC на Биткоин-ETF
Так вот, тру-Биткоин фондов одобрили сразу не 1, а аж 11 (чтобы никому обидно не было). Теперь вложиться в BTC можно прямо через брокерский счет, с издержками на уровне всего 0,2%+ годовых. Для сравнения: ранее фонд Grayscale GBTC (первая появившаяся биржевая альтернатива) с кривоватым отслеживанием цены Биткоина стоил в 10 раз больше – аж 2% годовых.
Кстати, этот самый GBTC тоже разрешили конвертнуть в нормальный ETF – так что те, кто в декабре 2022-го покупал паи этого фонда со скидкой в 50% от справедливой цены Биткоинов внутри, знатно кайфанули (дисконт по итогу закрылся практически в ноль).
Как ни страно, после выхода новых ETF цена Биткоина отнюдь не устремилась «туземун»: она немножко поторговалась около $49k, а потом взяла и упала до $42-43k. Зато Эфир подскочил нормально на ~20% вверх: криптаны ожидают, что фонд на ETH разрешат следующим.
Символично, что 8 января чуваки из компании Astrobotic запустили ракету, которая должна была торжественно доставить криптокошелек с одним Биткоином на Луну. Ну вы поняли? Типа, Bitcoin to the Moon! Так вот, по последним новостям, у них там что-то поломалось в аппарате, и биток до Луны не долетит, увы. Памп отменяется!

Тот самый Биткоин, который безуспешно попытались отправить к коротышкам на Луну
Отдельный лол – это то, что Vanguard (цитадель пассивных инвесторов, которую основал Джон Богл) отрубил своим клиентам доступ к биржевым торгам новыми Биткоин-фондами: типа, не кошерно, приличным людям такую каку трогать нельзя. Странно, что они там вообще позволяют людям выбирать, что покупать – эффективнее было бы сразу каждому новому клиенту автоматически покупать классический портфель 60/40 на всю котлету!
Рубрика «нейро-лол недели»: продавцы на Амазоне начали использовать ChatGPT для быстрой генерации названий и описаний товаров. Проверять, что там нейросетка накалякала, времени ни у кого нет – так что сейчас на маркетплейсе куча товаров с названиями в стиле «Извините, по политике OpenAI я не могу генерировать названия товаров и указывать какие-либо торговые марки...»
What a time to be alive!
В ChatGPT встроили персонализацию: некоторые пользователи пишут, что им пришло уведомление о том, что нейросетка теперь будет пытаться запоминать детали из разных диалогов с одним и тем же человеком – чтобы становиться «более полезной для него».
Неиронично ожидаю, что кому-то ChatGPT с учетом этой фичи напишет: «Знаешь, я тут перечитала все наши диалоги за последний месяц и поняла, что ты скучный душнила. Не пиши мне больше!»
Тут такое дело: на прошлой неделе Сэм Альтман из OpenAI вышел замуж.
Ниже фото молодоженов. Строго предупреждаю: на территории РФ смотреть ну эту картинку запрещается! Если вы случайно посмотрели – то на всякий случай срочно пересмотрите что-нибудь из фильмографии Евы Эльфи, чтобы нейтрализовать эффект.

Больше финансовых новостей и авторской аналитики у меня в Телеграм-канале RationalAnswer.


