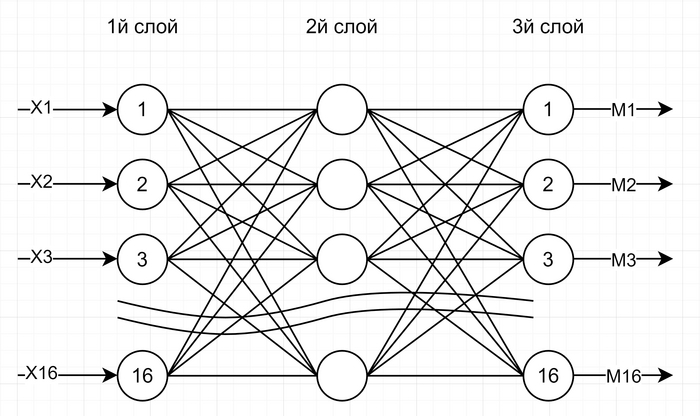
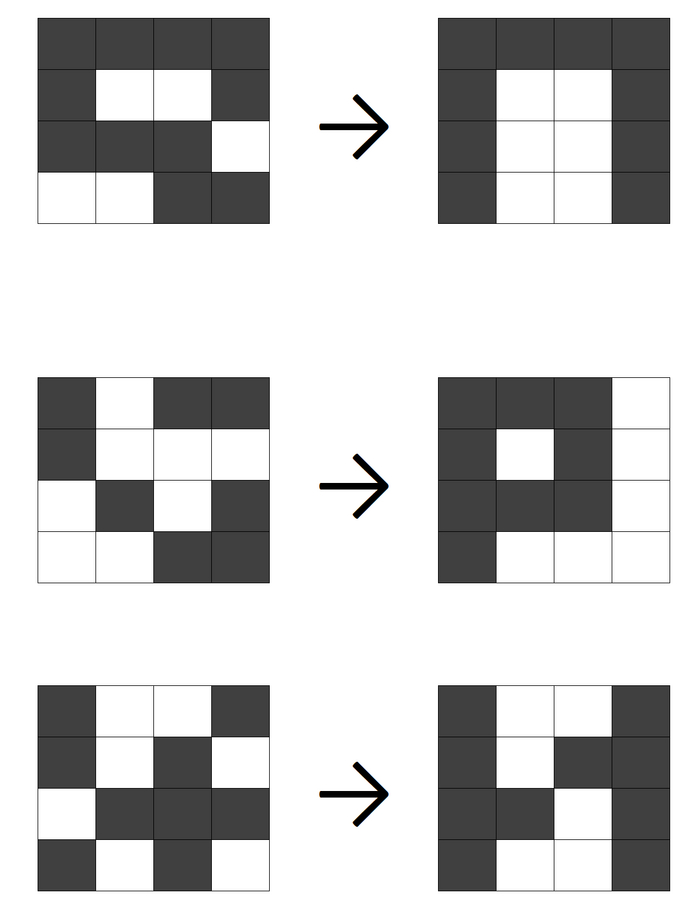
Простой пример рабочей сети.
Рассмотрим пример сети, которая будет заниматься распознаванием примитивных картинок. В процессе обучения мы "запишем" в сеть несколько образов. Затем, в процессе использования, мы будем подавать на вход искаженные образы, а сеть должна будет определить, какой же образ имелся в виду.
В качестве "картинок" мы будем использовать поле 4х4 пикселя, причем каждый пиксель может быть либо закрашен (тогда на вход подается 1), либо не закрашен (тогда на вход подается 0). Количество входов, соответственно, равно 16, т.е. по одному входу на каждый пиксель. Пример картинки:
Выходов у нас тоже будет 16, т.е. на каждый пиксель. Номера входов и выходов будут соответствовать порядковому номеру пикселя: с 1го по 4 - верхняя строка, с 5 по 8 - вторая строка и так далее. Нейронная сеть в общем будет выглядеть следующим образом:
Напомню функции составных частей сети:
Каждый нейрон вычисляет сумму всех приходящих на него значений, а затем округляет полученное число: если оно больше 0, то на выходе устанавливает значение 1, иначе - 0.
Каждая связь (синапс) имеет свой коэффициент (множитель). Значение, установленное на выходе нейрона, передается на каждый нейрон следующего слоя с умножением на вес соответствующего синапса.
Процесс обучения выглядит следующим образом:
Подаем на вход один из оригинальных образов;
Смотрим, что получается на выходе;
Вычисляем ошибку на каждом выходе;
Корректируем веса синапсов;
Повторяем операцию с другими образами до тех пор, пока ошибка не исчезнет.
Поясню третий пункт: так как на вход мы подали оригинальный образ, то ясно, что после "распознавания" нейронной сетью, он не должен поменяться. Поэтому ошибку, например, на 1-м выходе, можно вычислить как:
С учетом того, что на входах и выходах у нас всегда либо 0, либо 1, то ошибки могут принимать значения: 0, 1, -1.
Четвертый пункт достоин отдельного поста, так как в нем заложена вся суть метода обратного распространения ошибки. Но пока что нам нужно понять в целом, как работает обучение, поэтому на пальцах скажем следующее:
Если ошибка на выходе какого-то нейрона равна 0, то все веса на входных связях правильные, их не корректируем.
Если ошибка на выходе равна 1, т.е. вход больше, чем выход, значит, сигнал слишком ослабляется. Увеличим веса на небольшое значение, называемое шагом обучения. Порядок шага обучения для нашего примера - 0,01.
Если ошибка на выходе равна -1, значит, веса нужно, наоборот, уменьшить.
С учетом этих соображений, для синапса, проходящего от нейрона номер i к нейрону с номером j, вес после корректировки можно определить следующим образом:
Где step - шаг обучения, e_j - ошибка на выходе j-го нейрона, а g_ij - коэффициент, учитывающий влияние изменения веса синапса на выходное значение при текущих значениях входа. Рассмотрим, например, нейрон №1 третьего слоя: он связан со всеми нейронами второго слоя. Если на выходе какого-то из нейронов второго слоя установилось значение 0, то, как ни меняй вес синапса, соединяющего этот нейрон с нашим, значение на нашем нейроне не изменится, ведь вес будет умножаться на 0. Поэтому производить корректировку этого синапса на основании данных текущего примера бессмысленно. А вот если на выходе нейрона второго слоя установилась 1, то при изменении веса синапса, соединяющего его с нашим нейроном №1, выходное значение нашего нейрона может измениться, т.е. можно исправить ошибку за счет корректировки веса.
На самом-то деле у коэффициента g куда более интересный математический смысл, но об этом - в отдельном посте.
Что ж, здесь мы вплотную подошли к этапу, где нам потребуется немножко математики. Прежде чем приступить к ней, посмотрим, как работает наша сеть после обучения.
Подадим на вход искаженные образы, и посмотрим, как распознает их система: