

Расскажите можно ли устроится айтишником в СИБУР после университета?
Интересует мнение тех кто работал в этой компании. Я уже получил высшее образование, сходил на срочку и имею небольшой опыт работы.
Обучают ли они молодых специалистов в сфере IT?
Интересует мнение тех кто работал в этой компании. Я уже получил высшее образование, сходил на срочку и имею небольшой опыт работы.
Обучают ли они молодых специалистов в сфере IT?

После этого поста, где я сознался, что мне надоел фриланс и решил податься в найм, некоторые пикабушники почему-то решили, что я сижу без работы, и накидали мне заказов.
Удивлен изобретательности местных предпринимателей. Помимо привычного было то, о чем я бы не догадался.
К примеру, я бы не смог сообразить, что телеграм-бота можно выгодно использовать для:
Бронирования услуг парикмахерских
Заказа еды от местных ресторанов и кафе
Использования в качестве приложения для CRM-системы O_o
Онлайн-знакомств
Приложения такси
В общем, с развитым воображением у пикабушников оказалось все нормально.
Также дядька Алексей Н. очень помог с резюме, есть что проработать. Спасибо тебе.
Были и курьезные просьбы:
Удалить фотки с сайта
Накрутить отзывы в маркетплейсе
Ну ё-мае, вы с этим не ко мне, а к кул-хацкерам))
В общем, получилось забавно. Насколько я понял из комментариев к тому посту и из личных бесед, до февраля с наймом можно не дергаться, да и заказы сами себя не сделают.
В общем, всех с наступающим Новым годом и благодарю за обратную связь!
Недавно я запускал и тестировал Marco o1. Это одна из первых опенсорсных языковых моделей с многоступенчатой логикой, эта модель использует Chain-of-Thoughts и некоторые другие алгоритмы, которые помогают с решением задач на математику, логику и кодинг. Marco-o1 названа по аналогии с OpenAI o1, благодаря которой Chain-of-Thoughts промптинг и файнтюнинг получил особую популярность в GenAI индустрии.
В последнее время разные компании, в основном из Китая, стремятся повторить возможности o1. Самые впечатляющие результаты - у DeepSeek-R1-Lite-Preview, но веса этой модели не были опубликованы на момент проведения моих тестов. Однако разработчики DeepSeek R1 Lite обещали открыть доступ в свое время, и это будет очень интересно для нас.
А пока я решил поиграть с весами Marco-o1, модели хотя и легковесной, но реализующей те продвинутые алгоритмы, которые стоят за удивительными возможностями оригинальной o1. Как видно из карточки модели на HuggingFace, она создана путем файнтюнинга Qwen 2 7B на Chain-of-Thoughts датасете. Это комбинация датасетов Open-O1 и двух дополнительных наборов данных, которые разработчики из Alibaba Cloud сгенерировали, используя разные стратегии промптинга - Chain of Thoughts и обычные инструкции. Опубликована, к сожалению, только часть данных, но по ним ясно видно, какой формат использовали для файнтюнинга Chain-of-Thoughts:

Сам по себе Chain-of-Thoughts - это формат промпта, который заставляет модель строить цепочки мыслей вроде этой. Но как в случае с моделью Marco, чтобы нейросеть могла эффективно работать с таким форматом, ее нужно файнтюнить на Chain-of-Thoughts датасете. Точно так же Instruct модель требует файнтюнинга на данных с определенной структурой промптов и ответов.
Marco o1 также использует алгоритм поиска по дереву Монте-Карло (MCTS), который, согласно статье разработчиков, позволяет исследовать несколько путей рассуждения, используя показатель достоверности, полученный из логарифмических вероятностей топ-K альтернативных токенов. К этому значению вероятности для каждого токена и к пяти альтернативным значениям применяют функцию softmax и получают показатель достоверности C(i) для i-того токена. Потом вычисляют среднее значение для всех пяти альтернатив. Более высокое среднее значение показывает большую уверенность в том, что выбранный путь рассуждения является более оптимальным.
Пользуясь этим методом, языковая модель может исследовать разные пути рассуждения и выбирать среди них те, которые с большей вероятностью ведут к решению проблемы.

Изображение взято из статьи Marco-o1: Towards Open Reasoning Models for Open-Ended Solutions
Дальше есть еще пара интересных идей, например, Action Selection. Чтобы использовать только что описанный алгоритм MCTS, нужно определиться, что использовать в качестве единицы в пространстве решений, или одного шага рассуждения, и для этого разработчики применяли разные подходы - как целый шаг или действие в качестве единицы, так и мини-шаг - 32 или 63 токена.
Наконец, разработчики добавили механизм саморефлексии, в виде промпта в конце каждой цепочки рассуждений, который побуждает модель проверить свои решения: "Подожди, может быть я сделал какие-то ошибки, мне нужно обдумать все сначала". Это позволяет модели критически оценивать собственные рассуждения и находить в них ошибки.
А теперь немного практической части. Веса модели Marco-o1 имеют всего 7 миллиардов параметров. Я запускал ее и локально, и в облаке, в обоих случаях особо мощная видеокарта не требуется, особенно если применять квантизацию. Локально я запустил модель на RTX 4060 c 4-битной квантизацией bitsandbytes.
У меня была идея задеплоить полноценный LLM-server, совместимый с openai или gradio клиентом, и я выбрал два решения:
Первое - Text Generation Inference: на этот сервер уже был обзор на моем YouTube-канале, он высокопроизводительный, поддерживается платформой Huggingface, предлагает квантизацию и другие полезные фичи из коробки.
Запустить TGI локально не проблема, простой и правильный путь - в докере. Иначе придется устанавливать Rust и прочие зависимости, это ни к чему. Команда для запуска:
docker run --gpus all --shm-size 1g -p 8080:80 -v $path_to_volume:/data \
ghcr.io/huggingface/text-generation-inference:2.4.1 --model-id AIDC-AI/Marco-o1 --quantize bitsandbytes-nf4
Докер должен поддерживать GPU, что вообще не проблема на Linux или на Windows с WSL2. Флаг --quantize опциональный - можете выбрать опцию bitsandbytes (по умолчанию 8 бит) или вообще без сжатия, если есть достаточно видеопамяти.
В итоге на 4060 инференс получился очень быстрый. Я использовал следующий код для фронтенда на gradio:
статье.
import gradio as gr
from huggingface_hub import InferenceClient
client = InferenceClient("http://127.0.0.1:8080")
def respond(
message,history: list[tuple[str, str]],
system_message,
max_tokens,
temperature,
top_p,
):
messages = [{"role": "system", "content": system_message}]for val in history:
if val[0]:
messages.append({"role": "user", "content": val[0]})
if val[1]:
messages.append({"role": "assistant", "content": val[1]})
messages.append({"role": "user", "content": message})
response = ""
for message in client.chat_completion(messages,
max_tokens=max_tokens,
stream=True,
temperature=temperature,
top_p=top_p,
):
token = message.choices[0].delta.contentresponse += token
yield response
system_prompt = """You are a well-trained AI assistant, your name is Marco-o1. Created by AI Business of Alibaba International Digital Business Group.
## IMPORTANT!!!!!!
When you answer questions, your thinking should be done in <Thought>, and your results should be output in <Output>.<Thought> should be in English as much as possible, but there are 2 exceptions, one is the reference to the original text, and the other is that mathematics should use markdown format, and the output in <Output> needs to follow the language of the user input.
"""
demo = gr.ChatInterface(
respond,
additional_inputs=[
gr.Textbox(value=system_prompt, label="System message"),
gr.Slider(minimum=1, maximum=2048, value=1, step=1, label="Max new tokens"),
gr.Slider(minimum=0.1, maximum=4.0, value=0.7, step=0.1, label="Temperature"),
gr.Slider(
minimum=0.1,
maximum=1.0,
value=0.95,
step=0.05,
label="Top-p (nucleus sampling)",
),
],
)
if __name__ == "__main__":
demo.launch()
Однако я столкнулся с одной проблемой - системный промпт. Он взят из ollama, которая с таким промптом прекрасно работает. А вот TGI выдает ошибку, когда промпт превышает определенную длину. Так что для тех, кто не хочет возиться, предпочтительнее будет ollama, с ней все просто:
ollama pull marco-o1
ollama serve
А о том, как запустить ollama как сервис, чтобы создать таким образом свой LLM-сервер, я расскажу в следующей статье.


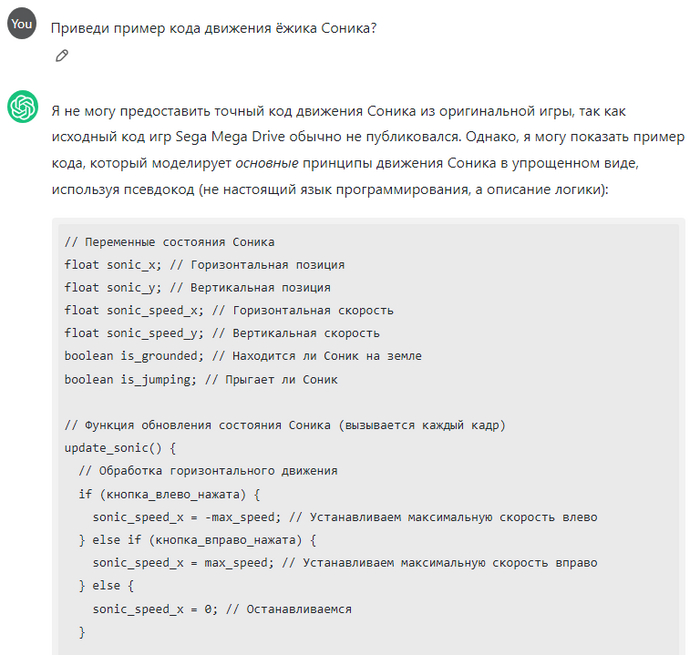


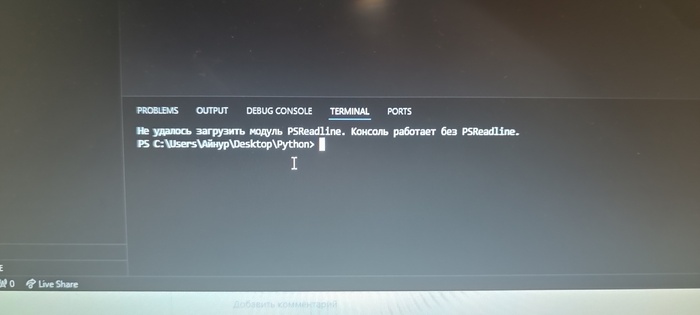
В последнее время появляется такая ерунда в терминале Visual Studio Code: "Не удалось загрузить модуль PSReadLine. Консоль работает без PSReadLine."
В папке модулей WindowsPowerShell он есть. Командами remove не удаляется.
Была до этого проблема с чтением путей кириллицы в верхнем регистре. Удалил командой remove этот PSReadLine, потом удалил папку с модулем и заново установил через терминал. Потом вот такая ерунда началась (с чтением путей проблем больше нет). Сам я новичок в VSCode, начал учить Python.
Как починить? 😥
Помогло следующее:
1. Переименование папки пользователя на латиницу. Гуглим как. С массовой заменой значений в реестре поможет RegWorks.
2. В повершеле написать:
Set-ExecutionPolicy RemoveSigned
И нажимаем Y
Товарищи из Google! Я знаю, это ваши проделки, не отрицайте! В остальных приложениях, кроме хрома, подсказки работают нормально. И только в хроме эта дурацкая лупа с результатами поиска!
Вы навязываете пользователям установку своего продукта, а именно гугл клавиатуры, которая нахрен мне не уперлась! Понимате, НАХРЕН НЕ УПЕРЛАСЬ!
СОВЕСТИ У ВАС НЕТ НИКАКОЙ!!!!
Быть новичком в IT непросто. К счастью, сообщество разработчиков всегда готово прийти на помощь. Мы попросили начинающего кодера Анну поделиться своими наблюдениями и лайфхаками по изучению языка Java Script.

Я еще в самом начале пути JavaScript-разработчика, но уже поняла несколько вещей, которые упрощают процесс. Поэтому делюсь информацией для тех, кто начинает изучение этого языка или только думает о входе в IT.
Даже несложные задачи вроде вывода текста в консоль постепенно приучают к работе с кодом. Универсальный вариант — учебник JavaScript на learn.javascript. Здесь после каждого урока есть упражнения. А еще с практикой вам помогут сайты-задачники Codewars и LeetCode.
Зазубривание теории не научит мыслить как разработчик. Учитесь категоризировать информацию, разбивать ее на части, выделять в них главное и запоминать это. Такой подход поможет сохранить в памяти самое важное из теории. А все остальное всегда можно посмотреть в интернете.
В любом деле ошибки — это нормально. А в нашем — даже хорошо. Они показывают, что именно работает не так в программе. Например, SyntaxError говорит о проблеме в синтаксисе кода вроде коварной пропущенной запятой или закрывающей скобки. Поэтому важно не только побороть огорчение при встрече с ошибками, но и разобраться в их типах.
Не забывайте: каждая ошибка — это урок, а не поражение. Они учат видеть больше, думать глубже и находить нестандартные решения. И это точно не повод забросить программирование.
Составьте подробный план: начните с основ JavaScript, затем изучите DOM, работу с API и фреймворки. Разбейте обучение на этапы, чтобы не перегружать себя. Главное — двигаться шаг за шагом, не пропуская практику. С этим поможет курс frontend-разработки на JavaScript от Kata Academy. Программа включает все для старта в IT и получения профессии. А оплатить обучение можно после трудоустройства.
Порой не получается самостоятельно решить проблему в коде. В этом случае обратитесь за помощью к искусственному интеллекту: современные нейросети ищут информацию по вашим запросам и приводят выжимку с пояснениями. Это даже удобнее, чем использовать поисковики.
Или воспользуйтесь туториалами от разработчиков с форума Stack Overflow. Но сначала их нужно отыскать. Формулируйте запрос четко: указывайте язык, технологию и текст ошибки. Не «ошибка 'x' undefined, что делать», а «JavaScript TypeError: Cannot read property 'x' of undefined». И разбирайтесь в найденном. Копирование кода без понимания только замедлит обучение.
Этот навык особенно пригодится в дальнейшем при работе с фреймворками. А для основной документации JavaScript есть удобная энциклопедия MDN Web Docs. Например, вам интересен принцип работы метода array.map(). Заходим на MDN и получаем: подробное описание метода, синтаксис, примеры использования, а также пояснения, какие типы данных он принимает и что возвращает.
Не пытайтесь сразу вникнуть в материалы вроде «Пишем интернет-магазин с нуля на JavaScript с фреймворками React & Node.JS». На первых порах эти видео напугали меня обилием информации. Всему свое время — начните с курсов, где достаточно внимания уделяют базовым понятиям. Такие материалы есть на каналах вроде itProger или Bogdan Stashchuk. А если понимаете, что самостоятельно не справитесь, начните учиться в школе программирования.
В программировании ошибки и тупики — естественная часть процесса. Не опускайте руки, если что-то не получается сразу. Я сама много раз думала, что ситуация безнадежна, и мне не стать программистом. JavaScript — гибкий язык, и часто одну задачу можно решить разными способами. Ищите обходные пути и экспериментируйте.
Начните изучение JavaScript в Kata Academy. Мы поможем вам приобрести и структурировать знания, получить практический опыт, собрать первое портфолио. А наши менторы всегда подскажут верное направление, если что-то будет непонятно.
Реклама ООО «Ката Академия», ИНН: 7802925162
Например, что-то пропадает. У одних важные вещи, у других новогоднее настроение. В этот раз — потерялись помощники Деда Мороза. Но есть хорошая новость: вы можете их найти! Вернее, помочь им найтись…
Прошел очередной спринт курсов. Опять было совсем несложно. Опять сделал все за день(может два, уже не помню точно), опять неделю развлекался задачками. Пет-проект застрял на моменте "в консоли все работало, добавил активити на compose(решил сразу учиться с него, ибо как будто бы за ним будущее) и получаю белый экран". Скилла разобраться в чем проблема, конечно же, не хватает.
В общем по хардам - продолжаю сам себя обучать, получать какой-то дофамин и интересные кейсы из курсов, и начинаю сильно грустить.
Про борьбу с алкоголизмом - на фоне скуки и печали пить стал сильно больше. Примерно каждый третий день по 3 литры пенного, что категорически меня не устраивает. Да, скука и печаль - не оправдание. Дело во мне. Будем работать над собой.
Попробовал закинуть резюме на вакансии android-developer. Просто посмотреть как реагируют HR-ы на "очередного оленя с курсов". Отправил 3 резюме, на одно не ответили, на второе выслали тестовое задание (логика несложная, но там нужно собрать в copmpose, еще и multiplatform), третьи написали "если готов к релокации - го на техническое собеседование" (вот это прям сильно удивило, что даже с HR разговаривать не надо). В общем, как будто бы, при определенной настойчивости работу найти вполне себе возможно. Так что будем продолжать учиться и стараться. Долой грусть тоску!





